
Chẩn đoán Hình ảnh Nhập môn: Các Nguyên lý và Dấu hiệu Nhận biết, Ấn bản thứ 5
Tác giả: William Herring, MD, FACR – © 2024 Nhà xuất bản Elsevier
Ths.Bs. Lê Đình Sáng (Chủ biên Bản dịch tiếng Việt)
Phụ lục Điện tử G: Trí tuệ Nhân tạo và Chẩn đoán Hình ảnh
Artificial Intelligence and Radiology
William Herring, MD, FACR
Learning Radiology, e-Appendix G, e101-e110
Lời giới thiệu
Trí tuệ nhân tạo (AI) là một lĩnh vực của khoa học máy tính, chuyên về việc mô phỏng các hành vi thông minh của con người bằng máy tính. AI được sử dụng để dự đoán, tự động hóa, tăng cường và tối ưu hóa các công việc mà trước đây do con người thực hiện.
Để có cái nhìn tổng quan về một số thuật ngữ chính và mối quan hệ giữa chúng, hãy xem Hình G.1 (mỗi thuật ngữ sẽ được thảo luận trong chương này).
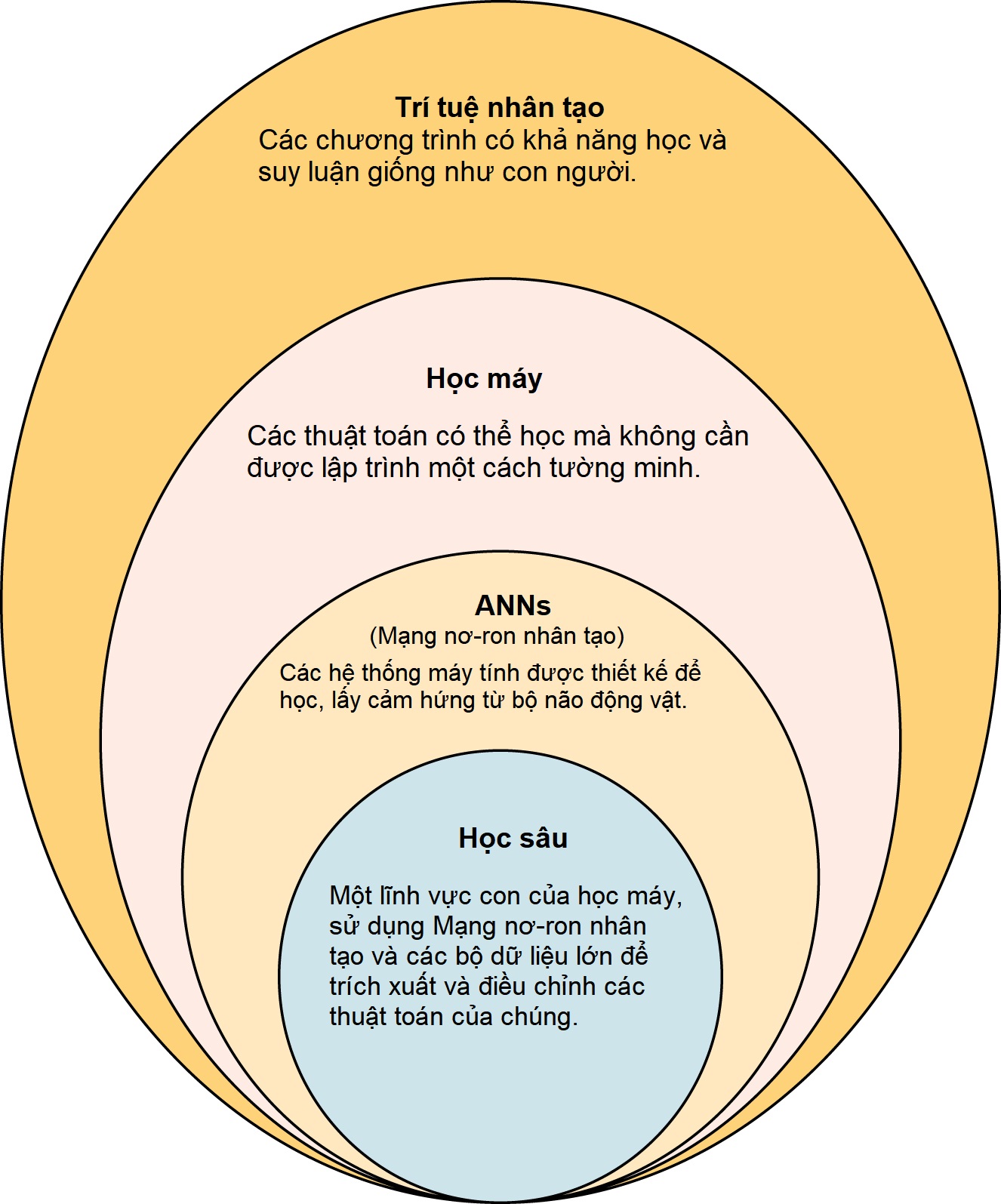
Hình G.1 Học máy là một lĩnh vực con của trí tuệ nhân tạo. Học sâu là một lĩnh vực con của học máy. Mạng nơ-ron nhân tạo (ANN) được sử dụng trong một số mạng học máy và tất cả các mạng học sâu. Có một bảng thuật ngữ AI ở cuối chương này.
Những người tiên phong
Alan Turing
- Nhiều người coi Alan Turing, nhà khoa học máy tính và nhà phân tích mật mã lỗi lạc người Anh trong Thế chiến II (và là nhân vật chính trong bộ phim The Imitation Game), là “cha đẻ” của trí tuệ nhân tạo.
Năm 1951, ông đã đề cập đến vấn đề mà sau này được gọi là trí tuệ nhân tạo. Ông cho rằng, một máy tính có thể vượt qua “bài kiểm tra Turing” nếu một người không thể phân biệt được sự khác biệt trong một cuộc trò chuyện bằng văn bản giữa những người khác và máy tính.
Ông nói, nếu máy tính vượt qua bài kiểm tra, nó sẽ cho thấy bằng chứng về “suy nghĩ”. Kể từ đó, bài kiểm tra Turing đã trở thành một thuật ngữ ngắn gọn để chỉ bất kỳ AI nào có thể thuyết phục một người tin rằng họ đang nhìn thấy hoặc tương tác với một người thật.
Vào thời điểm đó, Turing không thể thực hiện bài kiểm tra do ông đề xuất trên một máy tính thực tế vì không có máy tính nào đủ mạnh để chạy nó.
Một giải thưởng thường niên mang tên ông được trao như là sự công nhận cao quý nhất trong lĩnh vực khoa học máy tính.
John McCarthy
Năm 1956, John McCarthy, một trợ lý giáo sư toán học tại Đại học Dartmouth ở New Hampshire, đã chọn thuật ngữ trí tuệ nhân tạo trong một đề xuất cho một hội thảo mùa hè nhằm trao đổi ý tưởng về các cỗ máy suy nghĩ tại trường đại học. Hội nghị này, với sự tham dự của các nhà toán học, nhà khoa học máy tính và nhà tâm lý học nhận thức, được nhiều người coi là sự kiện khai sinh của trí tuệ nhân tạo.
Năng lực tính toán
Sự thiếu hụt năng lực xử lý của máy tính cùng với khó khăn trong việc tiếp cận lượng dữ liệu huấn luyện phù hợp đã ảnh hưởng đến những tiến bộ ban đầu của AI.
Trí tuệ nhân tạo đòi hỏi một năng lực tính toán khổng lồ để xử lý dữ liệu. AI không thể trở thành hiện thực nếu không có một bước nhảy vọt về năng lực xử lý của máy tính.
Vào thời điểm diễn ra Hội nghị Dartmouth năm 1956, máy tính tiên tiến nhất do IBM chế tạo. Nó chiếm cả một căn phòng, lưu trữ dữ liệu trên băng cassette và nhận lệnh bằng thẻ đục lỗ.
Năm 2020, chiếc iPhone 12, có thể nằm gọn trong túi của một người bình thường, có thể thực hiện 11 nghìn tỷ phép tính mỗi giây, gấp 55.000.000 lần so với máy tính IBM năm 1956.
Và vào năm 2018, siêu máy tính hiện đại nhanh nhất thế giới lúc bấy giờ có thể thực hiện một phép tính trong 1 giây mà chiếc máy tính IBM “cũ” phải mất gần 32.000 năm để hoàn thành.
Một phần lớn của sự gia tăng tốc độ tính toán đó đến từ việc nhận ra rằng phần cứng được gọi là đơn vị xử lý đồ họa (GPU) có thể tăng tốc đáng kể tốc độ xử lý do khả năng quản lý đồng thời các khối dữ liệu lớn một cách nhanh chóng (Hộp G.1).
| Hộp G.1 Đơn vị xử lý đồ họa (GPU)
Sự phát triển của mạng nơ-ron nhân tạo và việc chúng tạo điều kiện cho cuộc cách mạng học sâu là nhờ vào ngành công nghiệp trò chơi máy tính. Các trò chơi máy tính đòi hỏi hiệu suất đồ họa được tăng tốc, và kết quả là sự phát triển của đơn vị xử lý đồ họa (GPU), có thể chứa hàng nghìn lõi xử lý trên một con chip duy nhất. Các nhà nghiên cứu nhận ra rằng kiến trúc của GPU rất có giá trị trong việc phát triển mạng nơ-ron nhân tạo. |
Mạng Nơ-ron Nhân tạo (Mạng Nơ-ron, ANN)
Mạng nơ-ron nhân tạo (mạng nơ-ron hoặc ANN) được lấy cảm hứng từ mạng nơ-ron trong não động vật và dựa trên cách thức hoạt động gần đúng của não người.
Giống như các nơ-ron của chúng ta nhận tín hiệu điện từ các nơ-ron khác, năng lượng điện bên trong thân tế bào của chúng tăng lên cho đến khi đạt đến một ngưỡng kích hoạt nhất định, lúc đó tín hiệu điện sẽ truyền xuống sợi trục và được chuyển đến một nơ-ron khác. Quá trình này được lặp lại nhiều lần. Thông qua các sợi nhánh của mỗi nơ-ron, một nơ-ron đơn lẻ trong não kết nối với hàng nghìn nơ-ron khác.
Trong một ANN, các tập hợp nơ-ron phần mềm (được gọi là nút hoặc nơ-ron) được kết nối với nhau và được cấu hình để chúng có thể gửi thông điệp cho nhau. Nút nhận (postsynaptic) xử lý (các) tín hiệu của nó dưới dạng số hoặc bit mà máy tính có thể sử dụng và sau đó, lần lượt gửi tín hiệu đến các nút xuôi dòng được kết nối với nó. Mỗi nút được kết nối với mọi nút khác trong lớp tiếp theo và mỗi kết nối có trọng số riêng.
- Trọng số là phương tiện mà ANN học hỏi. Thông qua việc điều chỉnh các trọng số, ANN quyết định mức độ tín hiệu được truyền đi. Trọng số này có thể thay đổi khi quá trình học diễn ra, điều này lần lượt làm tăng hoặc giảm cường độ của tín hiệu mà các nút truyền đi xuôi dòng.
Một mạng nơ-ron có thể bao gồm hàng nghìn hoặc thậm chí hàng triệu nút xử lý đơn giản được kết nối với nhau.
Các hệ thống này học (tức là, ngày càng cải thiện khả năng của chúng) để thực hiện các tác vụ bằng cách phân tích các ví dụ, chủ yếu mà không cần lập trình cụ thể cho tác vụ.
Ví dụ, một tập dữ liệu huấn luyện có thể đã được gán nhãn thủ công trước đó và bao gồm hàng nghìn hình ảnh được gắn thẻ của thuyền, ô tô và máy bay, nhưng mạng sẽ tự tìm thấy các mẫu hình ảnh trong những hình ảnh đó mà tương quan một cách đáng tin cậy với mỗi thẻ của chúng để phân loại chúng vào các danh mục phù hợp.
Trong chẩn đoán hình ảnh, các ANN chuyên biệt có thể học cách xác định các hình ảnh chứa nốt phổi bằng cách phân tích các hình ảnh ví dụ đã được gán nhãn thủ công là nốt phổi và sử dụng các kết quả đã học để xác định nốt phổi trong các hình ảnh khác, chưa xác định.
Mạng nơ-ron được yêu cầu giải quyết một vấn đề lặp đi lặp lại, mỗi lần củng cố các kết nối dẫn đến thành công và giảm bớt các kết nối dẫn đến thất bại.
Hầu hết các mô hình học sâu hiện đại đều dựa trên mạng nơ-ron nhân tạo.
Các lớp (Layers)
Để thực hiện các phân tích này, các nút thường được tổ chức thành các nhóm, được gọi là lớp (Hình G.2).
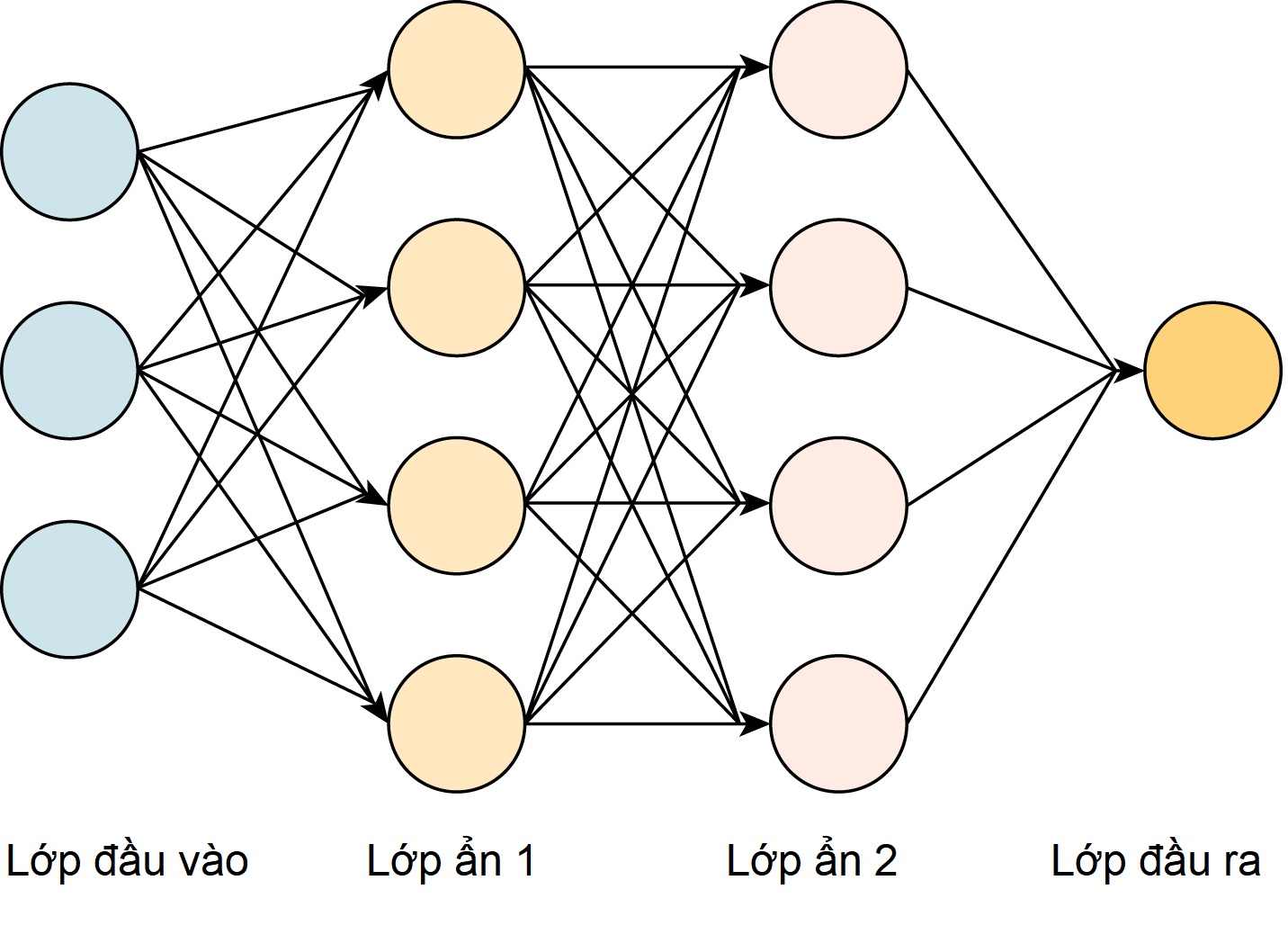
Hình G.2 Các lớp. Tất cả các mạng nơ-ron đều được tạo thành từ ít nhất ba loại lớp. Mỗi nút (được biểu thị bằng các vòng tròn có màu) của lớp đầu vào đại diện cho một đặc trưng duy nhất. Đặc trưng là các đặc điểm của tập dữ liệu. Có ít nhất một lớp trung gian, giữa lớp đầu vào và lớp đầu ra, nơi tất cả các tính toán được thực hiện, được gọi là (các) lớp ẩn. Mỗi lớp ẩn có chức năng và mức độ kích hoạt riêng với khả năng truyền thông tin từ lớp trước sang lớp tiếp theo. Một mạng nơ-ron bao gồm nhiều hơn ba lớp (bao gồm cả lớp đầu vào và đầu ra) có thể được coi là một mô hình học sâu. Chính số lượng lớp ngày càng tăng trong một mạng đã tạo nên “chiều sâu” trong học sâu. Cuối cùng, lớp đầu ra tạo ra (các) kết quả cho các đầu vào đã cho.
Lớp đầu vào có thể là một hình ảnh, hoặc các phần của một hình ảnh. Sau đó, có một số lớp ẩn có chức năng trích xuất các đặc trưng hình ảnh. Cuối cùng, có lớp đầu ra, trả lời câu hỏi mà mạng được thiết kế để trả lời.
Mỗi nút nhận một đầu vào, thực hiện một phép tính và xuất ra một giá trị cho lớp tiếp theo. Đầu vào của mỗi nút được tạo thành từ đầu ra của tất cả các nút trong lớp trước đó. Theo truyền thống, các lớp ẩn được kết nối đầy đủ, nghĩa là mọi nút trong lớp ẩn đầu tiên được kết nối với mọi nút trong lớp thứ hai, lớp này lại được kết nối với mọi nút trong lớp thứ ba, v.v.
Một phần của các phép tính mà mỗi nút thực hiện liên quan đến việc xác định trọng số của đầu ra của nó, có ảnh hưởng trực tiếp đến cách dữ liệu đầu vào được biến đổi và truyền từ nút này sang nút khác. Quá trình xác định giá trị của các trọng số, mà cuối cùng sẽ cung cấp đầu ra chính xác, được gọi là quá trình huấn luyện.
Để huấn luyện một mạng nơ-ron sâu một cách chính xác, dữ liệu ví dụ (chẳng hạn như hình ảnh) tạo thành đầu vào, và đầu ra chính xác tương ứng là câu trả lời đúng đã biết cho hình ảnh đó – sự thật nền (ground truth).
Quy trình huấn luyện thường được thực hiện bằng cách sử dụng ba tập dữ liệu độc lập với nhau, nghĩa là tất cả chúng phải chứa các ví dụ khác nhau. Chúng là: tập huấn luyện, tập kiểm định và tập kiểm tra. Các tập dữ liệu này được sử dụng trong ba bước khác nhau của quá trình huấn luyện (Hộp G.2).
| Hộp G.2 Các tập dữ liệu Huấn luyện, Kiểm định và Kiểm tra
Lý do chia dữ liệu thành các tập khác nhau là để tránh việc “học vẹt” và quá khớp (overfitting). Điều này nhằm ngăn chặn, ở mức độ có thể, hệ thống chỉ hoạt động tốt trên dữ liệu mà nó đã ghi nhớ trong tập huấn luyện nhưng lại tổng quát hóa kém đối với bất kỳ nguồn dữ liệu mới nào khác.
|
Sự khác biệt giữa đầu ra của mô hình và sự thật nền có thể được biểu thị dưới dạng sai số. Ví dụ, hãy tưởng tượng mạng của chúng ta được cho là sẽ tính toán xác suất một hình ảnh chứa nốt phổi. Một hình ảnh chứa một nốt phổi đã biết được đưa vào hệ thống và mạng tạo ra kết quả cho biết 20% khả năng có nốt phổi. Chúng ta biết rằng câu trả lời tốt nhất, trong trường hợp này, phải là 100% khả năng có nốt phổi. Chúng ta nhận ra đây là một sai số 80%, có nghĩa là cần phải làm việc nhiều hơn.
Việc tính toán sai số này được thực hiện cho mỗi hình ảnh trong tập huấn luyện và được kết hợp để thu được tổng sai số của mạng trên toàn bộ tập huấn luyện bằng cách cộng các sai số cho tất cả các hình ảnh trong tập huấn luyện.
Để giảm thiểu tổng sai số này, một số phương pháp được sử dụng, một trong số đó được gọi là lan truyền ngược (backpropagation), được thực hiện bằng cách điều chỉnh tất cả các trọng số bắt đầu từ lớp đầu ra và hoạt động ngược trở lại lớp đầu vào. Hệ thống thực hiện điều này bằng cách tìm ra trọng số nào chịu trách nhiệm cho các sai số và thay đổi các trọng số đó cho phù hợp.
Quy trình huấn luyện này cuối cùng sẽ tạo ra một mô hình có sai số rất nhỏ khi được sử dụng trên tập dữ liệu mà nó đã được huấn luyện (tức là tập huấn luyện).
- Tuy nhiên, điều có thể xảy ra trong phần huấn luyện này là mạng học quá nhiều từ các ví dụ trong tập huấn luyện, vô tình xác định các mẫu không chỉ trong tín hiệu mà còn cả trong nhiễu và cho rằng nhiễu là vốn có trong cấu trúc cơ bản của đầu vào. Điều này dẫn đến hiệu suất ấn tượng trên tập huấn luyện nhưng hiệu suất yếu khi được cung cấp dữ liệu mới. Đây được gọi là quá khớp (overfitting), và nó có nghĩa là hiệu suất của mạng không thể tổng quát hóa được.
Để giúp xác định và điều chỉnh cho tình trạng quá khớp, một tập dữ liệu độc lập khác được sử dụng để đánh giá hiệu suất của mạng. Tập dữ liệu đó được gọi là tập kiểm định. Việc sử dụng tập kiểm định được thực hiện trong quá trình huấn luyện để xem mô hình hoạt động tốt như thế nào trên dữ liệu mà nó chưa từng thấy. Nếu mạng hoạt động tốt trên tập huấn luyện ban đầu nhưng kém trên tập kiểm định, thì đã có tình trạng quá khớp, và cần phải thực hiện các điều chỉnh bằng cách sử dụng dữ liệu bổ sung hoặc các quy trình khác.
Bước cuối cùng sử dụng một tập dữ liệu khác cũng chưa được mạng nhìn thấy trước đây, đó là tập kiểm tra. Thuật toán xử lý các hình ảnh trong tập kiểm tra và hiệu suất của nó, ví dụ, độ chính xác trong việc tìm ra một nốt, được tính toán. Đây là một bài kiểm tra khách quan về cách thuật toán hoạt động trên dữ liệu chưa từng được mạng nhìn thấy trước đây (Hộp G.3).
| Hộp G.3 Vấn đề Hộp đen (The Black Box Problem)
AI thực hiện một lượng lớn các phép toán phức tạp, đặc biệt là trong các lớp ẩn của mạng nơ-ron nhân tạo. Các phép tính này thường không thể được con người hiểu, nhưng hệ thống vẫn mang lại thông tin hữu ích. Khi điều này xảy ra, nó được gọi là học hộp đen. Số lượng lớp ẩn được xây dựng trong mạng nơ-ron nhân tạo càng lớn, mô hình càng trở nên phức tạp, cũng như các phép tính đang được sử dụng.
Đây là một vấn đề quan trọng đối với các sự kiện trong cuộc sống của chúng ta đòi hỏi sự diễn giải của con người. Ví dụ, một hệ thống dự đoán tuổi thọ của bệnh nhân dựa trên một phim X-quang ngực có vẻ bình thường có thể sẽ khiến bệnh nhân khăng khăng muốn biết tại sao và quyết định đó được đưa ra như thế nào. Các mạng nơ-ron phức tạp đến mức dẫn đến vấn đề hộp đen có thể khiến người dùng khó chấp nhận. |
Mạng Nơ-ron Tích chập (CNN)
Mạng nơ-ron tích chập (CNN hoặc ConvNet) xứng đáng được đề cập đặc biệt vì chúng là kiến trúc mạng nơ-ron nhân tạo phổ biến nhất được sử dụng để xử lý hình ảnh y tế. Chúng được lấy cảm hứng từ đường dẫn thị giác của động vật và chúng hiệu quả trong việc phát hiện đối tượng (trích xuất đặc trưng) và phân loại hình ảnh.
CNN đưa ra giả định rõ ràng rằng đầu vào của chúng là hình ảnh. Điều này cho phép mã hóa các thuộc tính nhất định vào kiến trúc của hệ thống và giảm bớt một số bước tiền xử lý.
Mạng nơ-ron tích chập áp dụng nhiều bộ lọc cho một hình ảnh đầu vào để tạo ra một tập hợp đặc trưng theo từng pixel, tóm tắt sự hiện diện và thuộc tính của các đối tượng được phát hiện từ hình ảnh đầu vào. CNN có thể xem xét các nhóm pixel trong một khu vực của hình ảnh và học cách tìm ra các mẫu không gian. Chúng thực hiện việc trích xuất này thông qua một quá trình toán học được gọi là phép tích chập (convolution).
Các bộ lọc là những lưới giá trị rất nhỏ quét một cách có hệ thống trên toàn bộ hình ảnh đầu vào, từng pixel một, và tạo ra một đầu ra đã được lọc, lúc đầu, sẽ có kích thước gần bằng hình ảnh đầu vào. Hệ thống quét lặp đi lặp lại mỗi đầu ra từ một lớp tích chập, gộp (pooling) các kết quả thành các mẫu ngày càng nhỏ hơn.
- Gộp (Pooling) giải quyết sự nhạy cảm của CNN đối với việc học vị trí chính xác của một đặc trưng trong bản đồ đặc trưng. Những thay đổi nhỏ về vị trí của đầu vào trong các ví dụ tiếp theo có thể khiến hệ thống tạo ra nhiều bản đồ cho cùng một đặc trưng, điều này sẽ không hữu ích.
Một lớp gộp là một lớp mới được thêm vào sau lớp tích chập, làm giảm kích thước của bản đồ đặc trưng, giảm tính toán cần thiết cho mạng và làm cho mô hình trở nên mạnh mẽ hơn đối với các biến thể trong thay đổi vị trí của các đặc trưng trong hình ảnh đầu vào.
Ở cuối một mạng nơ-ron tích chập là ít nhất một lớp kết nối đầy đủ. Kết nối đầy đủ có nghĩa là mọi đầu ra được tạo ra ở cuối mẫu con cuối cùng đều là đầu vào cho mỗi nút trong lớp kết nối đầy đủ này.
Chính tại đây, các đầu ra của bản đồ đặc trưng được gửi đến để phân loại.
Phân loại lấy các đặc trưng từ đầu ra của các lớp tích chập và xác định xem đầu ra có phải là thành viên của một lớp (ví dụ: nốt phổi hoặc không phải nốt phổi) hay là xác suất nó là thành viên của một lớp cụ thể (ví dụ: 80% khả năng đây là nốt phổi ác tính) (Hình G.3).
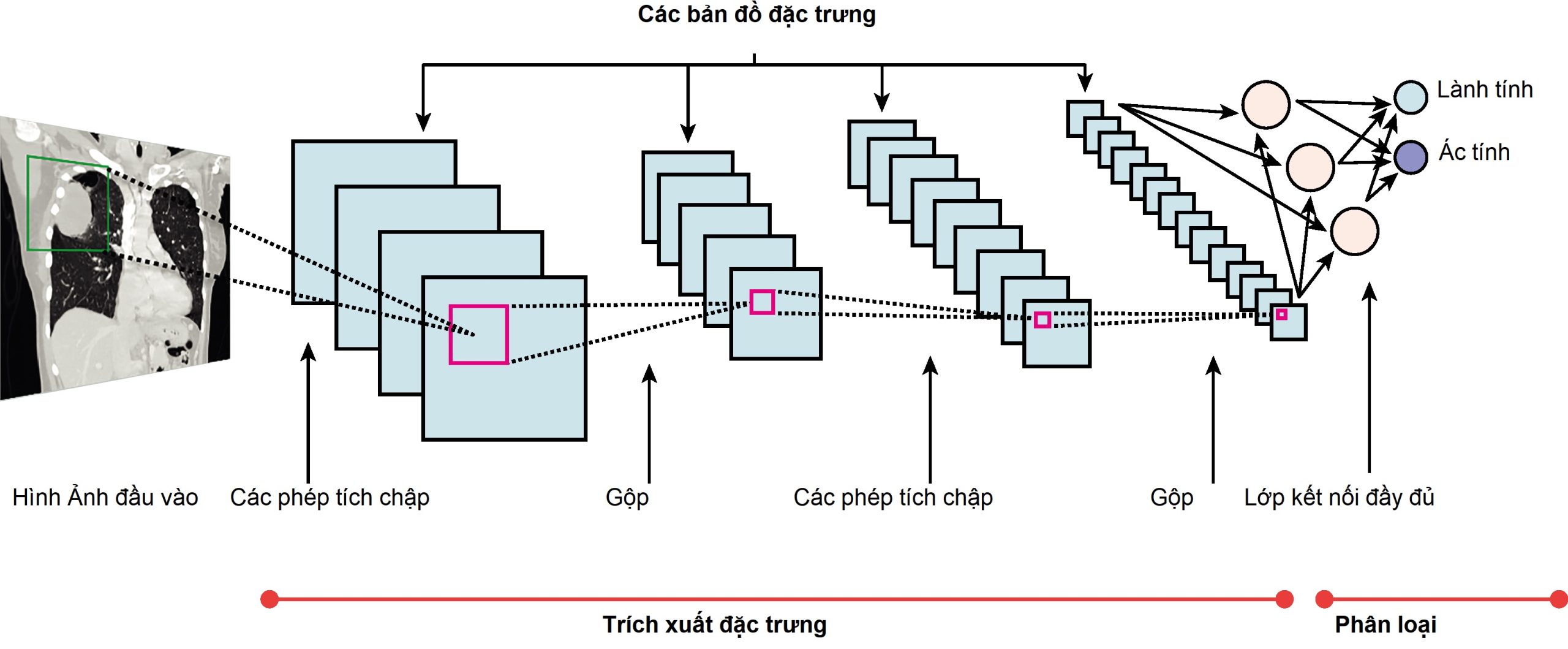
Hình G.3 Mạng Nơ-ron Tích chập. Nhiều bộ lọc được áp dụng một cách có hệ thống cho hình ảnh đầu vào để trích xuất các đặc trưng trải qua một phép tính toán học gọi là tích chập và một thao tác gọi là gộp. Gộp làm giảm kích thước của dữ liệu và giảm thiểu sự nhạy cảm của CNN đối với vị trí chính xác của các đặc trưng được trích xuất. Các lớp làm tăng độ phức tạp của các đặc trưng đã học, ví dụ, từ việc phát hiện các cạnh và đường trong lớp đầu tiên đến sự sắp xếp không gian của các cạnh và đường đó trong các lớp sâu hơn và cuối cùng là nhận dạng ý nghĩa của những sự sắp xếp đó khi được gửi đến các lớp kết nối đầy đủ để phân loại dữ liệu và tạo ra một đầu ra. Đầu ra có thể ở dạng một lớp, trong trường hợp giả định này, là hình ảnh đầu vào cho thấy ung thư phổi.
CNN là trung tâm của việc phân loại hình ảnh phi y tế, từ việc gắn thẻ một khuôn mặt trên Facebook đến an ninh và xe tự lái.
Học máy và Học sâu
Học máy (Machine Learning)
Học máy là một dạng của trí tuệ nhân tạo cho phép một hệ thống học hỏi từ dữ liệu thay vì thông qua lập trình tường minh. Một thuật toán học máy cho phép nó phát hiện các mẫu trong dữ liệu và đưa ra dự đoán khi không có các quy tắc và mô hình được lập trình sẵn. Bạn nên biết rằng một số tác giả sử dụng các thuật ngữ trí tuệ nhân tạo và học máy thay thế cho nhau.
Học sâu (Deep Learning)
- Học sâu xảy ra trong một ANN có nhiều hơn một lớp ẩn.
Học sâu có thể tự động hóa phần lớn quá trình trích xuất đặc trưng của quá trình huấn luyện, giúp loại bỏ một số sự can thiệp thủ công của con người. Nó có thể tiếp nhận dữ liệu phi cấu trúc ở dạng thô (ví dụ: từ văn bản hoặc hình ảnh) và có thể tự động xác định tập hợp các đặc trưng phân biệt đối tượng này với đối tượng khác. Học sâu học từ các ví dụ.
Một trong những khác biệt quan trọng nhất giữa học sâu và học máy truyền thống là hiệu suất của học sâu khi khối lượng dữ liệu tăng lên. Khi tập dữ liệu tương đối nhỏ, các thuật toán học sâu có thể không hoạt động tốt. Lý do là các thuật toán học sâu cần một lượng lớn dữ liệu để có thể học hỏi và hiểu rõ dữ liệu. Các thuật toán học máy sử dụng các quy tắc được xây dựng thủ công sẽ hoạt động tốt hơn với các tập dữ liệu nhỏ hơn.
- Học sâu không chỉ phát triển mạnh mẽ mà còn đòi hỏi rất nhiều dữ liệu. Con người có thể hình thành ấn tượng và đưa ra kết luận đáng tin cậy dựa trên dữ liệu không đầy đủ và không hoàn hảo, nhưng các mô hình học sâu đòi hỏi dữ liệu chất lượng để huấn luyện. Đây có thể là một hạn chế trong các lĩnh vực mà dữ liệu được chú thích ít có sẵn hoặc tốn kém để có được.
Các thuật toán học sâu phụ thuộc nhiều vào các máy móc tiên tiến với nhiều lớp và nhiều đơn vị xử lý đồ họa.
Học có giám sát và Học không giám sát
Hai phương pháp chính để dạy các mô hình là thông qua học có giám sát hoặc không giám sát.
Học có giám sát (Supervised Learning)
Trong học có giám sát, một mô hình được cung cấp dữ liệu đã được gán nhãn (gắn thẻ) một cách có hệ thống. Các nhãn thường được áp dụng bởi những người là chuyên gia trong lĩnh vực đó. Học có giám sát yêu cầu dữ liệu được sử dụng để huấn luyện thuật toán đã được gán nhãn với các câu trả lời đúng và các kết quả đầu ra có thể có của thuật toán đã được biết trước.
Đầu ra và độ chính xác của các thuật toán học có giám sát tương đối dễ đo lường (ví dụ: dữ liệu huấn luyện đầu vào được gán nhãn là mèo, hệ thống học, và khi được cung cấp dữ liệu mới, câu trả lời đầu ra của nó là mèo hoặc không phải mèo). Học có giám sát là một ứng dụng phổ biến của trí tuệ nhân tạo ngày nay và được sử dụng trong các ứng dụng như phát hiện biểu cảm khuôn mặt hoặc các đối tượng như biển báo dừng hoặc chữ số viết tay trên séc hoặc mã bưu chính.
Học không giám sát (Unsupervised Learning)
Học không giám sát cho phép máy tính tự tìm ra các mẫu mà không cần một tập dữ liệu chứa các câu trả lời đúng để học. Thuật toán phải tự giải mã các mối quan hệ giữa các dữ liệu. Trong nhiều trường hợp, hệ thống không được cung cấp câu trả lời đúng vì câu trả lời đúng có thể không thể xác định được đối với con người hoặc có thể không có một câu trả lời đúng duy nhất; có thể có hàng trăm hoặc hàng nghìn câu trả lời.
Trong học có giám sát, mục tiêu là dự đoán kết quả khi mô hình được giới thiệu với dữ liệu mới. Các kết quả mong đợi được biết trước – ví dụ, có hoặc không có tràn khí màng phổi.
Với một thuật toán học không giám sát, mục tiêu là thu được những hiểu biết sâu sắc từ khối lượng lớn dữ liệu mới. Bản thân mô hình sẽ xác định những gì khác biệt hoặc thú vị về các mục trong tập dữ liệu và rút ra suy luận từ những điểm tương đồng và khác biệt mà nó đã học được.
Ví dụ, học không giám sát được sử dụng trong các ứng dụng được gọi là hệ thống gợi ý (recommender applications) sử dụng dữ liệu như sở thích của khách hàng, đề xuất phim hoặc các mẫu mua sắm của người mua hàng để xếp khách hàng vào các nhóm khác nhau có sở thích tương tự dựa trên các giao dịch trong quá khứ. Sau đó, nó đề xuất các mặt hàng bổ sung mà mỗi nhóm có thể quan tâm. Đối với các ứng dụng AI như vậy, không có một câu trả lời đúng duy nhất.
Phát hiện/Chẩn đoán có Hỗ trợ của Máy tính trong Y học
Trong giai đoạn đầu phát triển các ứng dụng máy tính cho chẩn đoán trong y học, các nhà nghiên cứu đã cố gắng phát triển các hệ thống hoàn toàn tự động trong việc đưa ra chẩn đoán, điều này đã được chứng minh là không thực tế vào thời điểm đó.
Một trong những ứng dụng đầu tiên của phân tích máy tính được đưa vào y học đã xảy ra bên ngoài lĩnh vực chẩn đoán hình ảnh. Những nỗ lực đầu tiên để tự động hóa phân tích điện tâm đồ (ECG) là vào những năm 1970.
Điều thú vị cần lưu ý là hơn 50 năm kể từ khi giới thiệu các phân tích ECG tự động, các hội đồng chuyên gia vẫn khuyến nghị rằng tất cả các báo cáo điện tâm đồ dựa trên máy tính đều cần có sự đọc lại của bác sĩ.
- Phát hiện có sự hỗ trợ của máy tính (CADe) (“e” là viết tắt của detection – phát hiện) đã tìm thấy ứng dụng lớn nhất ban đầu trong chẩn đoán hình ảnh trong lĩnh vực chụp nhũ ảnh. Năm 1998, hệ thống CAD thương mại đầu tiên cho chụp nhũ ảnh đã được Cục Quản lý Thực phẩm và Dược phẩm Hoa Kỳ (FDA) phê duyệt. Các chương trình CAD tương đối sớm khác cũng tập trung vào việc nhận dạng gãy lún đốt sống trên phim X-quang nghiêng và phình động mạch nội sọ trên MRA.
Một số chương trình này chủ yếu phụ thuộc vào phần mềm nhận dạng mẫu được thiết kế để giảm thiểu bất kỳ sai sót tiềm ẩn nào trong quan sát. Chúng thực hiện điều này bằng cách áp dụng một lớp phủ điện tử đánh dấu bất cứ điều gì mà CAD xác định cần được đánh giá thêm sau khi các bác sĩ X-quang đã đọc lần đầu và trước khi đọc lần cuối.
Sàng lọc Phân loại Đơn giản có Hỗ trợ của Máy tính (CAST)
- Sàng lọc Phân loại Đơn giản có Hỗ trợ của Máy tính (CAST) là sự kết hợp giữa chẩn đoán có hỗ trợ của máy tính (CAD) và phân loại đơn giản và điều trị nhanh (START).
CAST thực hiện một diễn giải ban đầu hoàn toàn tự động của một ca chụp – một đánh giá sơ bộ, tập trung. Các ca chụp được phân tích bởi hệ thống sẽ tự động được phân loại vào một số lớp được xác định trước, ví dụ, nghi ngờ thuyên tắc phổi, nghi ngờ tràn khí màng phổi, v.v.
CAST đặc biệt có thể áp dụng trong chẩn đoán hình ảnh cấp cứu để hỗ trợ phân loại bệnh nhân có thể cần được chú ý ngay lập tức đối với các trường hợp cấp cứu có khả năng đe dọa tính mạng.
- Mặc dù mục tiêu chính của CAD truyền thống là hỗ trợ độ chính xác chẩn đoán của người đọc, CAST có thể giải quyết vấn đề ưu tiên trình tự đọc.
Hầu hết tất cả các cơ sở chẩn đoán hình ảnh đều tự động gán các ca chụp đã hoàn thành (tức là, kỹ thuật viên đã hoàn thành phần việc của họ, nhưng nó chưa được diễn giải) vào một danh sách (hàng đợi) các ca chưa đọc, với một dấu thời gian điện tử đánh dấu thời điểm ca chụp được hoàn thành.
Trong một số trường hợp, do khối lượng ca chụp hoặc loại ca, độ phức tạp của các ca, hoặc các yếu tố khác, có thể có những khoảng thời gian khác nhau trôi qua giữa việc hoàn thành ca chụp và việc diễn giải. Điều này có nghĩa là một số ca có thể bị đẩy xuống cuối hàng đợi các ca chưa đọc khi các ca mới được thêm vào, tạo ra kịch bản trong đó một ca chụp có phát hiện khẩn cấp tiềm tàng có thể không được diễn giải trước các ca khác không có mối đe dọa như vậy.
- Ưu tiên trình tự đọc cố gắng giảm thiểu vấn đề đó bằng cách tìm kiếm các tình trạng khẩn cấp được xác định trước ngay khi hình ảnh của chúng được thu nhận và tự động di chuyển các ca chụp đó lên đầu hàng đợi, thường có một số cờ hiệu để thu hút sự chú ý đến mối lo ngại đó.
Các ứng dụng của CAST
Có rất nhiều ứng dụng AI có sẵn từ nhiều nhà cung cấp và ngày càng nhiều ứng dụng được phê duyệt để sử dụng lâm sàng. Sau đây chỉ là một ví dụ.
- Thuyên tắc phổi (PE) Các chương trình này nhằm hỗ trợ các bác sĩ X-quang trong việc xác định các trường hợp nghi ngờ thuyên tắc phổi và gắn cờ các ca chụp đó để đẩy nhanh quá trình phân loại quy trình làm việc bằng cách truyền đạt các phát hiện nghi ngờ dương tính trên CT mạch máu ngực cho thuyên tắc phổi.
- Bóc tách động mạch chủ Các ứng dụng như vậy phân tích CT mạch máu ngực và bụng để hỗ trợ phát hiện bóc tách động mạch chủ.
- Đột quỵ Các ứng dụng đã được thiết kế để phân tích hình ảnh CT não có cản quang và gửi thông báo nếu phát hiện nghi ngờ tắc nghẽn mạch máu lớn. Cũng có các ứng dụng đánh giá CT não không cản quang để tìm các vùng giảm đậm độ và các mạch máu tăng đậm độ và phác thảo chúng, cũng hữu ích trong việc phát hiện đột quỵ.
- Gãy xương Tồn tại các ứng dụng cố gắng xác định và đánh dấu một khu vực mà nó thấy nghi ngờ có gãy xương của bộ phận xương đang được kiểm tra bằng X-quang quy ước.
- Tràn khí phúc mạc Các chương trình phát hiện khí tự do trong ổ bụng trên CT có cản quang đường uống để ưu tiên và phân loại các ca chụp đó đã được phát triển.
- Tràn khí màng phổi Có các thuật toán sẽ hỗ trợ phát hiện và định vị tràn khí màng phổi nghi ngờ và nâng các ca chụp này lên để đọc ưu tiên trong danh sách công việc.
- Xuất huyết nội sọ CT sọ không cản quang có thể được phân tích để tìm các đặc điểm gợi ý xuất huyết nội sọ cấp tính để ưu tiên và phân loại.
Các ứng dụng AI khác trong Chẩn đoán Hình ảnh
- Tầm soát ung thư vú bằng chụp nhũ ảnh Chụp nhũ ảnh là lĩnh vực chẩn đoán hình ảnh có tỷ lệ sử dụng CAD và AI cao nhất, theo một cuộc khảo sát do Hiệp hội Điện quang Hoa Kỳ (American College of Radiology) thực hiện. Có nhiều ứng dụng AI có sẵn để sử dụng trong chụp nhũ ảnh kỹ thuật số, chụp nhũ ảnh cắt lớp kỹ thuật số (tomosynthesis) và siêu âm vú. Chúng đã được chứng minh là hỗ trợ các bác sĩ X-quang trong việc tìm và phân loại các bất thường như khối u, biến dạng cấu trúc, bất đối xứng và vôi hóa.
- Thuyên tắc phổi Các hệ thống học sâu có thể đóng vai trò như một người đọc thứ hai để diễn giải và ưu tiên ngay lập tức các ca dương tính. Một mô hình học sâu cũng đã được phát triển có thể gắn cờ các bệnh nhân có gánh nặng cục máu đông cao hoặc căng thất phải để thu hút sự chú ý đến những bệnh nhân có thể có tiên lượng xấu hơn.
- Nhận dạng xuất huyết nội sọ AI đã được chứng minh là có thể phát hiện chính xác sự tồn tại và loại xuất huyết nội sọ trên CT sọ không cản quang với độ nhạy và độ đặc hiệu tương đối cao. Nó có tiềm năng hỗ trợ chẩn đoán chính xác xuất huyết nội sọ ở một số ít bệnh nhân ban đầu được cho là âm tính.
- Gãy lún đốt sống Tồn tại các thuật toán có thể được áp dụng cho một ca chụp CT ngực hoặc bụng để phát hiện gãy lún đốt sống.
- Phát hiện COVID-19 Sử dụng CT ngực làm đầu vào, các chương trình AI có sẵn sẽ phân tích phim chụp và làm nổi bật các khu vực có các mẫu phổi bất thường được biết là có liên quan đến COVID-19.
- Tuổi xương Có một ứng dụng có thể tự động phân tích phim X-quang bàn tay của trẻ em và tính toán tuổi xương, cũng như độ lệch chuẩn so với bình thường.
- Nốt phổi: Lành tính so với Ác tính Tồn tại các chương trình hỗ trợ phát hiện, phân loại và theo dõi sự phát triển của các nốt phổi.
- Hệ thống Hỗ trợ Quyết định Lâm sàng (CDSS) Các hệ thống hỗ trợ quyết định lâm sàng truyền thống sử dụng phần mềm được thiết kế để hỗ trợ việc ra quyết định lâm sàng bằng cách khớp các đặc điểm của bệnh nhân với một cơ sở kiến thức lâm sàng được máy tính hóa để đưa ra các khuyến nghị cho bác sĩ lâm sàng. Trong chẩn đoán hình ảnh, một trong những ứng dụng chính của hỗ trợ quyết định lâm sàng là hướng dẫn bác sĩ chỉ định đến phương pháp chẩn đoán hình ảnh phù hợp nhất, nếu có, cho mỗi bệnh nhân dựa trên tuổi, giới tính, tiền sử bệnh và các triệu chứng. Các hệ thống này đưa ra các khuyến nghị dựa trên một cơ sở dữ liệu máy tính hóa về các tiêu chí sử dụng phù hợp của các chuyên gia trong lĩnh vực, chẳng hạn như tiêu chí được phát triển bởi Hiệp hội Điện quang Hoa Kỳ có tên là ACR Appropriateness Criteria.
- Phát hiện polyp trên nội soi đại tràng ảo bằng CT CAD có sẵn để hỗ trợ bác sĩ X-quang trong việc xác định các polyp đại trực tràng trên nội soi đại tràng ảo bằng CT.
- Chụp CT mạch vành Có CAD để tự động phát hiện hẹp đáng kể (tức là, gây hẹp hơn 50%) của các động mạch vành trên các ca chụp CT mạch vành.
- Y học hạt nhân Tồn tại các hệ thống CAD để chẩn đoán di căn xương trên xạ hình xương toàn thân và bệnh động mạch vành trên hình ảnh tưới máu cơ tim.
- Mỡ gan Có các ứng dụng mô tả đặc điểm mô gan bằng cách cung cấp các phép đo định lượng về mỡ gan, xơ hóa và viêm.
Lợi ích
- Giảm sai sót Các nghiên cứu đã chỉ ra rằng chẩn đoán có sự hỗ trợ của máy tính kết hợp với sự diễn giải của con người có thể cải thiện nhỏ nhưng đáng kể độ chính xác tổng thể trong một số lĩnh vực hình ảnh học.
- Rút ngắn thời gian từ lúc chụp đến lúc có báo cáo Ưu tiên trình tự đọc có thể làm giảm thời gian từ khi hoàn thành ca chụp đến khi diễn giải và do đó giảm thời gian đưa ra các quyết định lâm sàng tiếp theo trong một số trường hợp mà thời gian có thể là yếu tố cốt lõi.
- Nền tảng mới cho sự thấu hiểu của con người Các mô hình trí tuệ nhân tạo có thể cung cấp thông tin mới mà chúng ta có thể sử dụng để phát triển những hiểu biết sâu sắc hoàn toàn của con người nhằm cải thiện việc chăm sóc bệnh nhân và các thuật toán mới hơn với tiện ích thậm chí còn lớn hơn. Có một giai thoại nổi tiếng về Archimedes, khi được giao nhiệm vụ xác định thành phần của vương miện của nhà vua, đã có khoảnh khắc “Eureka” khi ông bước vào một nhà tắm Hy Lạp và thấy rằng mực nước trong bồn tắm dâng lên, đột nhiên nhận ra ông có thể đo thể tích của vương miện bằng sự dịch chuyển của nước. Những khoảnh khắc “thay đổi nhận thức” hoặc “nhìn thấy các mối liên hệ” đột ngột như vậy được cho là độc nhất ở con người nhưng có thể được mô phỏng bởi AI.
Thách thức
- Dữ liệu lớn và chính xác Các hệ thống trí tuệ nhân tạo thường đòi hỏi một lượng lớn dữ liệu để huấn luyện. Các mô hình chỉ hiệu quả bằng dữ liệu được cung cấp cho chúng. Có thể mất một thời gian dài để thu thập đủ lượng dữ liệu và để con người phân tích nó theo cách mà máy tính sẽ thấy hữu ích. Cần có các bộ dữ liệu y tế lớn được chú thích tốt, vì nhiều thành tựu đáng chú ý nhất của học sâu đều dựa trên lượng dữ liệu rất lớn. Việc xây dựng các bộ dữ liệu như vậy trong y học rất tốn kém, đòi hỏi một khối lượng công việc khổng lồ của các chuyên gia, và cũng có thể đặt ra các vấn đề về quyền riêng tư và đạo đức. Như trong các lĩnh vực khác của AI, mục tiêu của các bộ dữ liệu y tế lớn là giảm thiểu tình trạng quá khớp và tăng khả năng tổng quát hóa.
- Những tuyên bố cường điệu về “độ chính xác” Đôi khi các công ty đưa ra những tuyên bố cường điệu rằng một xét nghiệm mới “chính xác gần 100%” trong việc chẩn đoán một bệnh nào đó. Mức độ chính xác chẩn đoán đó cao một cách đáng ngờ đối với bất kỳ vấn đề nào sử dụng AI. Khi các mô hình AI rời khỏi giai đoạn phát triển và bắt đầu đưa ra các dự đoán trong thế giới thực, hiệu suất của chúng gần như luôn xấu đi. Đó là lý do tại sao việc kiểm định độc lập là cần thiết trước khi sử dụng bất kỳ hệ thống AI mới và có tác động cao nào.
- Tính đặc thù của tác vụ Một đặc điểm chung của hầu hết các công cụ AI hiện tại là khả năng chỉ giải quyết một số lượng hạn chế các tác vụ cụ thể tại bất kỳ thời điểm nào, một thiếu sót của bất kỳ dạng trí tuệ hẹp nào. Trong một ví dụ giả định, một người kiểm tra một phim X-quang ngực duy nhất có thể xác định một nốt phổi, đồng thời nhận ra có 11 cặp xương sườn, tâm nhĩ trái bị giãn, có vôi hóa vỏ trứng của các hạch bạch huyết, và bóng hơi dạ dày bị lệch vào trong. Một hệ thống AI toàn diện có khả năng phát hiện nhiều bất thường không liên quan như vậy vẫn chưa được phát triển.
- Suy giảm kỹ năng của con người theo thời gian Năm 2013, Cục Hàng không Liên bang Hoa Kỳ đã ban hành một cảnh báo an toàn cho các phi công hàng không về việc sử dụng chế độ lái tự động ít hơn vì, họ nói, “việc sử dụng liên tục các hệ thống bay tự động (lái tự động) có thể dẫn đến sự suy giảm khả năng của phi công trong việc nhanh chóng phục hồi máy bay khỏi tình trạng không mong muốn” và “thật không may, việc sử dụng liên tục các hệ thống đó không củng cố kiến thức và kỹ năng của phi công trong các hoạt động bay thủ công.” Năm 2019, chiếc Boeing 737 MAX đã bị cấm bay trên toàn thế giới sau khi một hệ thống điều khiển bay dựa trên máy tính bị trục trặc đã khiến hai máy bay mới bị rơi ở Indonesia và Ethiopia, làm chết tất cả 346 người trên máy bay. Người ta cho rằng một phần của vấn đề là việc đào tạo phi công về hệ thống mới có thể đã không đầy đủ. Có một mối lo ngại rằng, theo thời gian, sự phổ biến của chẩn đoán dựa trên AI sẽ khiến ngày càng ít chuyên gia con người có thể giảng dạy hoặc xác nhận các mô hình máy tính.
- Tự động chấp nhận các chẩn đoán do AI tạo ra, đặc biệt trong các tình huống khẩn cấp Các bác sĩ X-quang, giống như các bác sĩ khác, thường yêu cầu ý kiến thứ hai từ các đồng nghiệp sau khi xem một hình ảnh để tìm kiếm lời khuyên bổ sung. Các chẩn đoán do AI tạo ra, đặc biệt là những chẩn đoán được tạo ra tự động bởi các ứng dụng ưu tiên đọc, có thể khác biệt trong cách tiếp cận này bằng cách đưa ra lời khuyên đó một cách tự nguyện trước khi bác sĩ có cơ hội đưa ra phán đoán của riêng mình. Trong một nghiên cứu thử nghiệm, được tiến hành bên ngoài việc chăm sóc bệnh nhân thực tế, sự chấp nhận của bác sĩ đối với lời khuyên do máy tính tạo ra, ngay cả khi một số trong đó đã bị các nhà điều tra cố tình thao túng để không chính xác, đã được chấp nhận trong nhiều trường hợp, đặc biệt nếu chuyên môn của những người nhận được lời khuyên không chính xác ban đầu thấp hơn so với một nhóm khác có chuyên môn cao hơn. Xu hướng tuân theo lời khuyên không chính xác đó được gọi là tính nhạy cảm lâm sàng (clinical susceptibility) và nó mang ý nghĩa đối với việc chấp nhận các diễn giải tự động, đặc biệt nếu có sự suy giảm đồng thời về chuyên môn của con người.
- Dương tính giả và âm tính giả Càng nhiều kết quả dương tính giả, độ đặc hiệu của bất kỳ xét nghiệm nào càng thấp. Nếu tỷ lệ dương tính giả cao, xét nghiệm không có tính đặc hiệu cao, điều này làm giảm sự chấp nhận của hệ thống CAD vì người dùng phải kiểm tra lại tất cả các kết quả sai. Trong các hệ thống CAST, nơi các ca chụp được gắn cờ tự động được chuyển lên đầu hàng đợi, tỷ lệ dương tính giả sẽ phải rất thấp nếu việc tối ưu hóa trình tự đọc được tin cậy.
- Vấn đề Hộp đen (xem Hộp G.3) Khi các mạng học sâu với ngày càng nhiều lớp thực hiện các phép tính dường như không rõ ràng để đi đến một kết quả có thể hành động, liệu con người có mất khả năng phán đoán tại sao và làm thế nào một quyết định được đưa ra không?
Dự đoán
Trí tuệ nhân tạo đã và sẽ tiếp tục hỗ trợ con người trong nỗ lực đạt được độ chính xác và an toàn tối đa trong chẩn đoán và điều trị y tế. Những dự đoán mang tính tương lai đã và sẽ tiếp tục được đưa ra, làm say mê nhiều người và khiến những người khác sợ hãi.
Tài liệu có rất nhiều dự đoán sai lầm về AI được đưa ra bởi một số người rất thông minh.
- Alan Newell, một nhà nghiên cứu hàng đầu về khoa học máy tính và là người đoạt giải Turing, đã nói vào năm 1958: “Trong vòng 10 năm, một máy tính kỹ thuật số sẽ là nhà vô địch cờ vua thế giới.” Ông đã đúng rằng một siêu máy tính của IBM tên là Deep Blue đã đánh bại nhà vô địch cờ vua thế giới lúc bấy giờ là Garry Kasparov. Tuy nhiên, thành tích ấn tượng nhưng hẹp về mặt lập trình đó đã xảy ra 40 năm sau dự đoán của Newell.
- H. A. Simon, một người đoạt giải Nobel, đã nói vào năm 1965: “Máy móc sẽ có khả năng, trong vòng 20 năm, thực hiện bất kỳ công việc nào mà một người đàn ông có thể làm.”
- Marvin Minsky, đồng sáng lập Phòng thí nghiệm AI của Viện Công nghệ Massachusetts và là một người đoạt giải Turing khác, đã nói vào năm 1970: “Trong từ ba đến tám năm, chúng ta sẽ có một cỗ máy với trí thông minh của một người bình thường.” Đã nhiều thập kỷ trôi qua kể từ khi ông dự đoán điều đó và, mặc dù có thể có một số cuộc thảo luận về những gì tạo nên trí thông minh của một người bình thường, chúng ta vẫn chưa đến gần dự đoán đó.
- Roy Amara là đồng sáng lập của Viện Tương lai, ở Thung lũng Silicon, và được biết đến với một câu nói, được gọi một cách thích hợp là định luật Amara:
Chúng ta có xu hướng đánh giá quá cao tác động của một công nghệ trong ngắn hạn và đánh giá thấp tác động trong dài hạn.
Bao nhiêu năm, thập kỷ, thậm chí thế kỷ, tạo nên ngắn hạn so với dài hạn là điều không dễ dự đoán và cũng không chắc sẽ đúng.
Bảng thuật ngữ
| Thuật ngữ | Định nghĩa |
|---|---|
| Thuật toán (Algorithm) | Một danh sách tuần tự các công thức toán học hoặc lệnh lập trình giúp máy tính có khả năng giải quyết vấn đề. |
| Trí tuệ nhân tạo (Artificial intelligence) | Trí tuệ nhân tạo (AI) là một lĩnh vực của khoa học máy tính, chuyên về việc mô phỏng các hành vi thông minh của con người bằng máy tính. Các lĩnh vực con chính của nó là học máy và học sâu. |
| Mạng nơ-ron nhân tạo (Artificial neural networks) | Một hệ thống máy tính lấy cảm hứng từ bộ não con người, thường chứa ít nhất một lớp đầu vào, gửi các đầu vào có trọng số đến một loạt các lớp ẩn và một lớp đầu ra ở cuối. |
| Lan truyền ngược (Backpropagation) | Một phương pháp huấn luyện mạng nơ-ron trong đó đầu ra ban đầu của hệ thống được so sánh với đầu ra mong muốn, sau đó được điều chỉnh cho đến khi sự khác biệt giữa các đầu ra là tối thiểu. |
| Học hộp đen (Black box learning) | AI thực hiện một lượng lớn các phép toán phức tạp, đặc biệt là trong các lớp ẩn của mạng nơ-ron nhân tạo. Các phép tính này thường không thể được con người hiểu, nhưng hệ thống vẫn mang lại thông tin hữu ích. Khi điều này xảy ra, nó được gọi là học hộp đen. |
| Mạng nơ-ron tích chập (Convolutional neural network – CNN) | CNN được thiết kế đặc biệt để xử lý hình ảnh. Mỗi lớp CNN chứa nhiều bộ lọc. Mỗi bộ lọc là một ma trận trọng số nhỏ, tương tự như trọng số của một mạng nơ-ron thông thường. Các bộ lọc được áp dụng lặp đi lặp lại cho các pixel hình ảnh, cho phép chúng nhận dạng các mẫu lặp lại. CNN lý tưởng cho việc phân tích hình ảnh vì hình ảnh được cấu tạo từ các mẫu lặp lại. |
| Học sâu (Deep learning) | Trí tuệ nhân tạo được thực hiện bởi các mạng nơ-ron có nhiều lớp ẩn. Học sâu có thể có giám sát hoặc không giám sát. |
| Trích xuất đặc trưng (Feature extraction) | Dữ liệu được lấy từ dữ liệu đầu vào có thể ở dạng các cạnh, đường, điểm, đốm, hoặc kết cấu, trong số những thứ khác. |
| Lớp (Layers) | Một sự sắp xếp của một nhóm các nút trong một mạng nơ-ron nhân tạo xử lý một tập hợp các đặc trưng đầu vào và tạo ra một kết quả. |
| Học máy (Machine learning) | Được nhiều người sử dụng thay thế cho trí tuệ nhân tạo. Học máy là quá trình mà AI sử dụng các thuật toán để thực hiện các chức năng của trí tuệ nhân tạo. |
| Mô hình (Model) | Một biểu diễn trừu tượng về những gì một mạng nơ-ron nhân tạo đã học được từ tập dữ liệu huấn luyện trong quá trình huấn luyện. |
| Xử lý ngôn ngữ tự nhiên (Natural language processing) | Khả năng của một mạng nơ-ron tiên tiến trong việc diễn giải ngôn ngữ của con người; được sử dụng trong các dịch vụ dịch thuật như Alexa và Siri. |
| Nơ-ron (Neurons) | Trong AI, được sử dụng thay thế cho thuật ngữ nút. |
| Nút (Nodes) | Các đơn vị tính toán có một hoặc nhiều kết nối đầu vào có trọng số, một hàm truyền kết hợp các đầu vào theo một cách nào đó, và một kết nối đầu ra. Các nút được tổ chức thành các lớp để tạo thành một mạng. |
| Quá khớp (Overfitting) | Một vấn đề phổ biến trong học máy là quá khớp: học một hàm giải thích hoàn hảo dữ liệu huấn luyện mà mô hình đã học nhưng không tổng quát hóa tốt cho dữ liệu kiểm tra chưa thấy. Quá khớp xảy ra khi một mô hình học quá mức từ dữ liệu huấn luyện đến mức nó học được những đặc điểm riêng không phải là biểu diễn vốn có của đầu vào. |
| Gộp (Pooling) | Quá trình giảm một ma trận được tạo ra bởi một lớp tích chập thành một ma trận nhỏ hơn, một phần để giảm các sai số do thay đổi vị trí của dữ liệu mới. |
| Độ nhạy (Sensitivity) | Một thước đo về tần suất một xét nghiệm trả về kết quả dương tính cho những người thực sự mắc bệnh đang được xét nghiệm (dương tính thật). |
| Độ đặc hiệu (Specificity) | Một thước đo về khả năng của một xét nghiệm tạo ra kết quả âm tính một cách chính xác cho những người không mắc bệnh đang được xét nghiệm (âm tính thật). Một xét nghiệm có độ đặc hiệu thấp được sử dụng để sàng lọc sẽ tạo ra một số lượng lớn người không mắc bệnh phải trải qua đánh giá thêm. |
| Học có giám sát (Supervised learning) | Máy tính học bằng các ví dụ được gán nhãn. Học có giám sát yêu cầu dữ liệu được sử dụng để huấn luyện thuật toán đã được gán nhãn với các câu trả lời đúng và các kết quả đầu ra có thể có của thuật toán đã được biết trước. |
| Tập dữ liệu huấn luyện (Training dataset) | Tập hợp các ví dụ được sử dụng để dạy mạng ban đầu – tức là, để huấn luyện thuật toán. Nó có thể chứa các ví dụ huấn luyện được gán nhãn chính xác. Mạng sẽ nhìn thấy và học hỏi từ dữ liệu này. |
| Tập dữ liệu kiểm tra (Testing dataset) | Tiêu chuẩn vàng được sử dụng để đánh giá mô hình. Nó chỉ được sử dụng một lần khi một mô hình đã được huấn luyện hoàn chỉnh (sử dụng tập huấn luyện và tập kiểm định). Tập dữ liệu này nhằm mục đích tái tạo thế giới thực và chưa từng được hệ thống nhìn thấy trước đây. |
| Học không giám sát (Unsupervised learning) | Máy tính được cung cấp dữ liệu và nó tự học bằng cách tự động tìm ra các mẫu và mối quan hệ bên trong tập dữ liệu đó. |
| Tập dữ liệu kiểm định (Validation dataset) | Một tập dữ liệu được sử dụng để tinh chỉnh, điều chỉnh trọng số và chọn mô hình tốt nhất trong quá trình huấn luyện. |
| Trọng số (Weights) | Cường độ kết nối giữa các đơn vị, hoặc các nút, trong một mạng nơ-ron. Các trọng số này có thể được điều chỉnh trong một quá trình gọi là học. |