
Thống kê Sinh học Cơ bản và Lâm sàng, Ấn bản thứ 5 – Basic & Clinical Biostatistics, 5e
Tác giả: Susan White – Nhà xuất bản McGraw-Hill Medical – Biên dịch: Ths.Bs. Lê Đình Sáng
Chương 3: Tóm tắt và Trình bày Dữ liệu bằng Bảng và Đồ thị
Summarizing Data & Presenting Data in Tables & Graphs
CÁC KHÁI NIỆM CHÍNH
|
CÁC VẤN ĐỀ TÌNH HUỐNG
Vấn đề Tình huống 1Tuổi thọ kỳ vọng thay đổi theo các vùng của Hoa Kỳ. Davids và cộng sự (2014) đã kiểm tra các Chỉ số Tình trạng Sức khỏe Cộng đồng (CHSI) để Chống Béo phì, Bệnh tim và Ung thư nhằm xác định các cơ hội cải thiện tình trạng sức khỏe và tuổi thọ kỳ vọng dựa trên các yếu tố xã hội quyết định sức khỏe đã biết. Họ đã tìm thấy mối liên hệ giữa tuổi thọ kỳ vọng và tình trạng nghèo đói, trình độ học vấn và thành phần chủng tộc của một hạt. Vấn đề Tình huống 2Nhiều bệnh nhân mắc các bệnh mãn tính không tham gia vào các hoạt động tự quản lý. Bos-Touwen và cộng sự (2015) đã điều tra các đặc điểm của những bệnh nhân tham gia vào các chương trình tự quản lý cho một số bệnh mãn tính bao gồm: Đái tháo đường týp 2 (DM-II), Bệnh phổi tắc nghẽn mãn tính (COPD), Suy tim mãn tính (CHF), và Bệnh thận mãn tính (CRD). Họ đã sử dụng một công cụ khảo sát gọi là Thước đo Mức độ Chủ động của Bệnh nhân 13 mục (PAM-13) cũng như các biến số nhân khẩu học, lâm sàng và tâm lý xã hội. Vấn đề Tình huống 3Anderson và cộng sự (2018) đã nghiên cứu các yếu tố dự báo bệnh cúm ở hơn 4.500 bệnh nhân đến bệnh viện với các triệu chứng giống cúm từ năm 2009 đến 2014. Họ thấy rằng các triệu chứng quan trọng nhất để dự báo bệnh cúm là ho, sổ mũi, ớn lạnh và đau nhức cơ thể. Họ đã xây dựng một mô hình dự đoán có thể dự đoán sự hiện diện/vắng mặt của virus cúm. Hơn nữa, họ đã kiểm tra giá trị dự đoán của một xét nghiệm cúm nhanh so với các trường hợp cúm được xác nhận bằng virus học. |
MỤC ĐÍCH CỦA CHƯƠNG
Chương này giới thiệu các loại dữ liệu khác nhau được thu thập trong nghiên cứu y học và trình bày cách tổ chức và trình bày các bản tóm tắt dữ liệu. Bất kể nghiên cứu cụ thể nào đang được thực hiện, các nhà điều tra đều thu thập các quan sát và thường muốn chuyển chúng thành các bảng hoặc đồ thị hoặc trình bày các con số tóm tắt, chẳng hạn như phần trăm hoặc giá trị trung bình. Từ góc độ thống kê, không quan trọng các quan sát là về người, động vật, vật vô tri hay sự kiện. Điều quan trọng là loại quan sát và thang đo mà chúng được đo lường. Những đặc điểm này quyết định các thống kê được sử dụng để tóm tắt dữ liệu, được gọi là thống kê mô tả (descriptive statistics), và các loại bảng hoặc đồ thị hiển thị và truyền đạt các quan sát một cách tốt nhất.
Dữ liệu từ các bộ dữ liệu chăm sóc sức khỏe mã nguồn mở được sử dụng để minh họa các bước liên quan đến việc tính toán các thống kê vì việc nhìn thấy các bước giúp hầu hết mọi người hiểu được các quy trình. Tuy nhiên, hầu hết mọi người sẽ sử dụng máy tính để phân tích dữ liệu. Trên thực tế, chương này và các chương sau chứa nhiều minh họa từ một số chương trình máy tính thống kê thường được sử dụng, bao gồm một chương trình thống kê mã nguồn mở có tên là R. Người đọc được khuyến khích tải xuống và cài đặt R để có thể tái tạo các bài tập được trình bày ở đây.
CÁC THANG ĐO LƯỜNG
Thang đo để đo lường một đặc điểm có ý nghĩa đối với cách thông tin được hiển thị và tóm tắt. Như chúng ta sẽ thấy trong các chương sau, thang đo lường—độ chính xác mà một đặc điểm được đo lường—cũng quyết định các phương pháp thống kê để phân tích dữ liệu. Ba thang đo lường thường xuất hiện nhất trong y học là danh nghĩa (nominal), thứ tự (ordinal), và số lượng (numerical).
Thang đo Danh nghĩa
Thang đo danh nghĩa (nominal scales) được sử dụng cho mức độ đo lường đơn giản nhất khi các giá trị dữ liệu phù hợp với các phạm trù. Một trường hợp đặc biệt của thang đo danh nghĩa chỉ ra sự hiện diện hay vắng mặt của một thuộc tính. Ví dụ, trong một nghiên cứu về tỷ lệ tử vong, những bệnh nhân tử vong có thể được gán nhãn là 1 trong khi những người sống sót có thể được gán nhãn là 0. Trong ví dụ này, các quan sát là nhị phân (dichotomous or binary) ở chỗ kết quả chỉ có thể nhận một trong hai giá trị: có hoặc không (chết hoặc sống). Mặc dù chúng ta nói về dữ liệu danh nghĩa như là trên thang đo lường, chúng ta không thực sự đo lường dữ liệu danh nghĩa; thay vào đó, chúng ta đếm số lượng quan sát có hoặc không có thuộc tính quan tâm.
Nhiều phân loại trong nghiên cứu y học được đánh giá trên thang đo danh nghĩa. Kết quả của một phương pháp điều trị y tế hoặc thủ thuật phẫu thuật, cũng như sự hiện diện của các yếu tố nguy cơ có thể có, thường được mô tả là xảy ra hoặc không xảy ra. Kết quả cũng có thể được mô tả với nhiều hơn hai phạm trù, chẳng hạn như phân loại thiếu máu thành hồng cầu nhỏ (bao gồm thiếu sắt), hồng cầu to hoặc nguyên hồng cầu khổng lồ (bao gồm thiếu vitamin ), và hồng cầu bình thường (thường liên quan đến bệnh mãn tính).
Dữ liệu được đánh giá trên thang đo danh nghĩa đôi khi được gọi là quan sát định tính (qualitative observations), vì chúng mô tả một chất lượng của người hoặc vật được nghiên cứu, hoặc quan sát phân loại (categorical observations), vì các giá trị phù hợp với các phạm trù. Dữ liệu danh nghĩa hoặc định tính thường được mô tả dưới dạng phần trăm hoặc tỷ lệ. Bảng ngẫu nhiên (contingency tables) và biểu đồ cột (bar charts) thường được sử dụng nhất để hiển thị loại thông tin này và được trình bày trong phần có tiêu đề “Bảng và Đồ thị cho Dữ liệu Danh nghĩa và Thứ tự.” Thuộc tính quan trọng của dữ liệu thang đo danh nghĩa là các phạm trù không được sắp xếp theo thứ tự; chúng chỉ đơn giản là các phạm trù được gán nhãn cho phép nhà nghiên cứu lập bảng kết quả.
Thang đo thứ bậc
Khi có một trật tự sẵn có giữa các phạm trù, các quan sát được cho là được đo trên một thang đo thứ bậc (ordinal scale). Các quan sát vẫn được phân loại, như với thang đo danh nghĩa, nhưng một số quan sát có giá trị nhiều hơn hoặc lớn hơn các quan sát khác. Các bác sĩ lâm sàng thường sử dụng thang đo thứ bậc để xác định mức độ nguy cơ của bệnh nhân hoặc loại liệu pháp phù hợp. Ví dụ, các khối u được phân giai đoạn theo mức độ phát triển của chúng. Phân loại quốc tế để phân giai đoạn ung thư biểu mô cổ tử cung là một thang đo thứ bậc từ 0 đến 4, trong đó giai đoạn 0 đại diện cho ung thư biểu mô tại chỗ và giai đoạn 4 đại diện cho ung thư biểu mô lan rộng ra ngoài tiểu khung hoặc xâm lấn niêm mạc bàng quang và trực tràng. Trật tự sẵn có trong thang đo thứ bậc này, tất nhiên, là tiên lượng cho giai đoạn 4 xấu hơn so với giai đoạn 0.
Các phân loại dựa trên mức độ của bệnh đôi khi liên quan đến mức độ hoạt động của bệnh nhân. Ví dụ, viêm khớp dạng thấp được phân loại, theo mức độ nghiêm trọng của bệnh, thành bốn cấp độ từ hoạt động bình thường (cấp 1) đến phải ngồi xe lăn (cấp 4). Mặc dù có trật tự giữa các phạm trù trong thang đo thứ bậc, sự khác biệt giữa hai phạm trù liền kề không giống nhau trong toàn bộ thang đo. Để minh họa, điểm Apgar, mô tả sự trưởng thành của trẻ sơ sinh, dao động từ 0 đến 10, với điểm thấp hơn cho thấy sự suy giảm chức năng tim mạch, hô hấp và thần kinh và điểm cao hơn cho thấy chức năng tốt. Sự khác biệt giữa điểm 8 và 9 có lẽ không có ý nghĩa lâm sàng giống như sự khác biệt giữa điểm 0 và 1.
Một số thang đo bao gồm điểm số cho nhiều yếu tố sau đó được cộng lại để có được một chỉ số tổng thể. Một chỉ số thường được sử dụng để ước tính nguy cơ tim mạch trong các thủ thuật phẫu thuật không phải tim mạch đã được Goldman và các đồng nghiệp của ông phát triển (1977, 1995). Chỉ số này gán điểm cho một loạt các yếu tố nguy cơ, chẳng hạn như tuổi trên 70, tiền sử nhồi máu cơ tim trong 6 tháng qua, các bất thường điện tâm đồ cụ thể, và tình trạng thể chất chung. Các điểm được cộng lại để có được một điểm số tổng thể từ 0 đến 53, được sử dụng để chỉ ra nguy cơ biến chứng hoặc tử vong cho các mức điểm khác nhau.
Một loại thang đo thứ bậc đặc biệt là thang đo xếp hạng (rank-order scale), trong đó các quan sát được xếp hạng từ cao nhất đến thấp nhất (hoặc ngược lại). Ví dụ, các nhà cung cấp dịch vụ y tế có thể hướng các nỗ lực giáo dục của họ nhắm vào bệnh nhân sản khoa dựa trên việc xếp hạng các nguyên nhân gây nhẹ cân ở trẻ sơ sinh, chẳng hạn như suy dinh dưỡng, lạm dụng ma túy và chăm sóc trước sinh không đầy đủ, từ phổ biến nhất đến ít phổ biến nhất. Thời gian của các thủ thuật phẫu thuật có thể được chuyển đổi thành thang đo xếp hạng để có được một thước đo về độ khó của thủ thuật.
Giống như thang đo danh nghĩa, phần trăm và tỷ lệ thường được sử dụng với thang đo thứ bậc. Toàn bộ tập dữ liệu được đo trên thang đo thứ bậc có thể được tóm tắt bằng giá trị trung vị (median), và chúng tôi sẽ mô tả cách tìm giá trị trung vị và ý nghĩa của nó. Các thang đo thứ bậc có số lượng lớn các giá trị đôi khi được coi như là số lượng (xem phần sau). Các loại bảng và đồ thị tương tự được sử dụng để hiển thị dữ liệu danh nghĩa cũng có thể được sử dụng với dữ liệu thứ tự.
Thang đo Số lượng
Các quan sát mà sự khác biệt giữa các con số có ý nghĩa trên một thang đo số lượng (numerical scale) đôi khi được gọi là quan sát định lượng (quantitative observations) vì chúng đo lường số lượng của một cái gì đó. Có hai loại thang đo số lượng: thang đo liên tục (continuous) (khoảng hoặc tỷ lệ) và thang đo rời rạc (discrete). Một thang đo liên tục có các giá trị trên một chuỗi liên tục (ví dụ: tuổi); một thang đo rời rạc có các giá trị bằng số nguyên (ví dụ: số lần gãy xương).
Nếu dữ liệu không cần phải rất chính xác, dữ liệu liên tục có thể được báo cáo đến số nguyên gần nhất. Tuy nhiên, về mặt lý thuyết, phép đo chính xác hơn là có thể. Tuổi là một thước đo liên tục, và tuổi được ghi nhận đến năm gần nhất thường sẽ đủ trong các nghiên cứu về người lớn; tuy nhiên, đối với trẻ nhỏ, tuổi đến tháng gần nhất có thể thích hợp hơn. Các ví dụ khác về dữ liệu liên tục bao gồm chiều cao, cân nặng, thời gian sống còn, phạm vi chuyển động của khớp và nhiều giá trị xét nghiệm.
Khi một quan sát số lượng chỉ có thể nhận các giá trị nguyên, thang đo lường là rời rạc. Ví dụ, các phép đếm sự vật—số lần mang thai, số lần phẫu thuật trước đó, số lượng các yếu tố nguy cơ—là các thước đo rời rạc.
Các đặc điểm được đo trên thang đo số lượng thường được hiển thị trong nhiều loại bảng và đồ thị. Giá trị trung bình (means) và độ lệch chuẩn (standard deviations) thường được sử dụng để tóm tắt các giá trị của các thước đo số lượng. Tiếp theo, chúng ta sẽ kiểm tra các cách tóm tắt và hiển thị dữ liệu số lượng và sau đó quay lại chủ đề về dữ liệu thứ tự và danh nghĩa.
TÓM TẮT DỮ LIỆU SỐ LƯỢNG BẰNG CÁC CON SỐ
Khi một nhà điều tra thu thập nhiều quan sát, chẳng hạn như điểm mức độ chủ động, chỉ số khối cơ thể (BMI), điểm tình trạng sức khỏe, và điểm chủ động của bệnh nhân trong nghiên cứu của Bos-Touwen và cộng sự (2015), các con số tóm tắt dữ liệu có thể truyền đạt rất nhiều thông tin.
Các Thước đo Trung tâm
Một trong những con số tóm tắt hữu ích nhất là một chỉ số về trung tâm của một phân phối các quan sát—giá trị trung tâm hoặc trung bình. Ba thước đo xu hướng trung tâm (central tendency) được sử dụng trong y học và dịch tễ học là trung bình cộng (mean), trung vị (median), và ở mức độ thấp hơn, yếu vị (mode). Cả ba đều được sử dụng cho dữ liệu số lượng, và trung vị cũng được sử dụng cho dữ liệu thứ tự.
Tính toán các Thước đo Xu hướng Trung tâm
Trung bình cộng: Mặc dù một số loại trung bình có thể được tính toán về mặt toán học, trung bình cộng số học (arithmetic mean), hay trung bình đơn giản, được sử dụng thường xuyên nhất trong thống kê và là loại thường được đề cập đến bằng thuật ngữ “trung bình”. Trung bình cộng là trung bình số học của các quan sát. Nó được ký hiệu là (đọc là X-ngang) và được tính như sau: cộng các quan sát để có được tổng và sau đó chia cho số lượng quan sát.
Công thức cho trung bình cộng được viết là , trong đó (chữ cái Hy Lạp sigma) có nghĩa là cộng, đại diện cho các quan sát riêng lẻ, và là số lượng quan sát.
Bảng 3-1 cung cấp giá trị của điểm mức độ chủ động, BMI, và Điểm Tổng hợp SF-12 cho 18 bệnh nhân được chọn ngẫu nhiên trong nghiên cứu tự quản lý (Bos-Touwen và cộng sự, 2015). (Chúng ta sẽ tìm hiểu về lấy mẫu ngẫu nhiên trong Chương 4.) Trung bình cộng của điểm mức độ chủ động cho 18 bệnh nhân này là 53,0.
Trung bình cộng được sử dụng khi các con số có thể được cộng lại (tức là, khi các đặc điểm được đo trên thang đo số lượng); nó thường không nên được sử dụng với dữ liệu thứ tự vì bản chất tùy ý của thang đo thứ bậc. Trung bình cộng rất nhạy cảm với các giá trị cực đoan trong một tập hợp các quan sát, đặc biệt là khi cỡ mẫu khá nhỏ. Ví dụ, giá trị 75,3 của đối tượng 1 tương đối lớn so với các giá trị khác. Nếu giá trị này không có, trung bình cộng sẽ là 51,7 thay vì 53,0.
Bảng 3-1. Điểm mức độ chủ động của một mẫu ngẫu nhiên 18 bệnh nhân.
| ID Đối tượng | BMI | Điểm Mức độ Chủ động | Điểm Tổng hợp SF12 | Tuổi |
|---|---|---|---|---|
| 1 | 25.5 | 75.3 | 90.8 | 57 |
| 2 | 22.9 | 56.4 | 54.6 | 76 |
| 3 | 29.4 | 68.5 | 86.3 | 64 |
| 4 | 30.4 | 60.0 | 57.5 | 65 |
| 5 | 23.1 | 56.4 | 70.8 | 62 |
| 6 | 31.3 | 37.3 | 13.8 | 64 |
| 7 | 27.5 | 52.9 | 21.3 | 84 |
| 8 | 24.5 | 70.8 | 91.7 | 68 |
| 9 | 28.5 | 52.9 | 38.8 | 80 |
| 10 | 25.1 | 56.4 | 26.3 | 82 |
| 11 | 25.0 | 52.9 | 36.3 | 61 |
| 12 | 24.2 | 47.4 | 88.8 | 57 |
| 13 | 25.1 | 60.0 | 30.4 | 92 |
| 14 | 28.8 | 34.7 | 21.3 | 66 |
| 15 | 28.4 | 38.7 | 24.2 | 52 |
| 16 | 22.8 | 45.2 | 44.2 | 69 |
| 17 | 31.6 | 36.0 | 31.3 | 79 |
| 18 | 29.1 | 52.9 | 75.0 | 56 |
Dữ liệu từ Bos-Touwen I, Schuurmans M, Monninkhof EM, và cộng sự: Các đặc điểm của bệnh nhân và bệnh liên quan đến sự chủ động tự quản lý ở bệnh nhân đái tháo đường, bệnh phổi tắc nghẽn mãn tính, suy tim mãn tính và bệnh thận mãn tính: một nghiên cứu khảo sát cắt ngang, PLoS One. 2015 Tháng 5, 7;10(5):e0126400.
Nếu không có các quan sát gốc, trung bình cộng có thể được ước tính từ một bảng tần suất. Một trung bình có trọng số được hình thành bằng cách nhân mỗi giá trị dữ liệu với số lượng quan sát có giá trị đó, cộng các tích lại, và chia tổng cho số lượng quan sát. Một bảng tần suất của các quan sát điểm mức độ chủ động được trình bày trong Bảng 3-2, và chúng ta có thể sử dụng nó để ước tính trung bình cộng của điểm mức độ chủ động cho tất cả 1.154 bệnh nhân trong nghiên cứu. Ước tính trung bình có trọng số, sử dụng số lượng đối tượng và các điểm giữa trong mỗi khoảng, là:
Bảng 3-2. Phân phối tần suất của điểm mức độ chủ động theo các khoảng 5 điểm.
| Điểm Mức độ Chủ động | Số lượng | Số lượng Tích lũy | Phần trăm | Phần trăm Tích lũy |
|---|---|---|---|---|
| 35 trở xuống | 11 | 11 | 0.95% | 0.95% |
| 35 đến dưới 40 | 50 | 61 | 4.33% | 5.29% |
| 40 đến dưới 45 | 148 | 209 | 12.82% | 18.11% |
| 45 đến dưới 50 | 292 | 501 | 25.30% | 43.41% |
| 50 đến dưới 55 | 130 | 631 | 11.27% | 54.68% |
| 55 đến dưới 60 | 191 | 822 | 16.55% | 71.23% |
| 60 đến dưới 65 | 151 | 973 | 13.08% | 84.32% |
| 65 đến dưới 70 | 65 | 1038 | 5.63% | 89.95% |
| 70 đến dưới 75 | 50 | 1088 | 4.33% | 94.28% |
| 75 đến dưới 80 | 43 | 1131 | 3.73% | 98.01% |
| 80 trở lên | 23 | 1154 | 1.99% | 100.00% |
Dữ liệu từ Bos-Touwen I, và cộng sự (2015).
Giá trị của trung bình cộng được tính từ một bảng tần suất không phải lúc nào cũng giống như giá trị thu được với các con số thô. Trong ví dụ này, các trung bình cộng của điểm mức độ chủ động được tính từ các con số thô và bảng tần suất rất gần nhau. Tất nhiên, các nhà điều tra tính toán trung bình cộng để trình bày trong một bài báo hoặc bài nói chuyện có các quan sát gốc và nên sử dụng công thức chính xác. Công thức sử dụng với một bảng tần suất hữu ích khi chúng ta, với tư cách là người đọc một bài báo, không có quyền truy cập vào dữ liệu thô nhưng muốn có một ước tính về trung bình cộng.
Trung vị: Trung vị (median) là quan sát ở giữa, tức là, điểm mà một nửa số quan sát nhỏ hơn và một nửa lớn hơn. Trung vị đôi khi được ký hiệu là M hoặc Md, nhưng nó không có ký hiệu quy ước. Quy trình tính trung vị như sau:
- Sắp xếp các quan sát từ nhỏ nhất đến lớn nhất (hoặc ngược lại).
- Đếm vào để tìm giá trị ở giữa. Trung vị là giá trị ở giữa đối với một số lượng quan sát lẻ; nó được định nghĩa là trung bình cộng của hai giá trị ở giữa đối với một số lượng quan sát chẵn.
Ví dụ, theo thứ tự xếp hạng (từ thấp nhất đến cao nhất), các giá trị điểm mức độ chủ động trong Bảng 3-1 là: 34.7, 36.0, 37.3, 38.7, 45.2, 47.4, 52.9, 52.9, 52.9, 52.9, 56.4, 56.4, 56.4, 60.0, 60.0, 68.5, 70.8, 75.3. Đối với 18 quan sát, trung vị là trung bình cộng của giá trị thứ chín và thứ mười (52.9 và 52.9), tức là 52.9. Trung vị cho chúng ta biết rằng một nửa số giá trị điểm mức độ chủ động trong nhóm này nhỏ hơn 52.9 và một nửa lớn hơn 52.9. Chúng ta sẽ tìm hiểu sau trong chương này rằng trung vị rất dễ xác định từ một biểu đồ thân-lá của các quan sát.
Trung vị ít nhạy cảm với các giá trị cực đoan hơn so với trung bình cộng. Ví dụ, nếu quan sát lớn nhất, 75.3, bị loại khỏi mẫu, trung vị sẽ là giá trị ở giữa, 52.9. Trung vị cũng được sử dụng với các quan sát thứ tự.
Yếu vị: Yếu vị (mode) là giá trị xuất hiện thường xuyên nhất. Nó thường được sử dụng cho một số lượng lớn các quan sát khi nhà nghiên cứu muốn chỉ định giá trị xuất hiện thường xuyên nhất. Giá trị 52.9 xuất hiện thường xuyên nhất trong dữ liệu ở Bảng 3-1. Do đó, yếu vị của điểm mức độ chủ động là 52.9. Khi một tập dữ liệu có hai yếu vị, nó được gọi là phân phối hai đỉnh (bimodal). Đối với các bảng tần suất hoặc một số lượng nhỏ các quan sát, yếu vị đôi khi được ước tính bằng lớp yếu vị (modal class), là khoảng có số lượng quan sát lớn nhất. Đối với dữ liệu điểm mức độ chủ động trong Bảng 3-2, lớp yếu vị là 45 đến 50 với 292 bệnh nhân.
Trung bình nhân: Một thước đo xu hướng trung tâm khác không được sử dụng thường xuyên như trung bình cộng hoặc trung vị là trung bình nhân (geometric mean), đôi khi được ký hiệu là GM hoặc G. Nó là căn bậc n của tích của n quan sát. Dưới dạng ký hiệu, đối với n quan sát , trung bình nhân là:
Lấy logarit của cả hai vế của phương trình trên, chúng ta thấy rằng logarit của trung bình nhân bằng với trung bình cộng của các logarit của các quan sát.
Sử dụng các Thước đo Xu hướng Trung tâm:
Thước đo xu hướng trung tâm nào là tốt nhất với một tập hợp các quan sát cụ thể? Hai yếu tố quan trọng: thang đo lường (thứ tự hoặc số lượng) và hình dạng của phân phối các quan sát. Mặc dù các phân phối được thảo luận chi tiết hơn trong Chương 4, ở đây chúng ta xem xét khái niệm về việc một phân phối có đối xứng qua trung bình cộng hay bị lệch (skewed) sang trái hoặc phải.
Nếu các quan sát ngoại lai chỉ xảy ra ở một hướng—hoặc một vài giá trị nhỏ hoặc một vài giá trị lớn—phân phối được cho là một phân phối lệch (skewed distribution). Nếu các giá trị ngoại lai nhỏ, phân phối bị lệch trái (skewed to the left), hay lệch âm (negatively skewed); nếu các giá trị ngoại lai lớn, phân phối bị lệch phải (skewed to the right), hay lệch dương (positively skewed). Một phân phối đối xứng (symmetric distribution) có hình dạng giống nhau ở cả hai bên của trung bình cộng. Hình 3-1 đưa ra các ví dụ về các phân phối lệch âm, lệch dương và đối xứng.
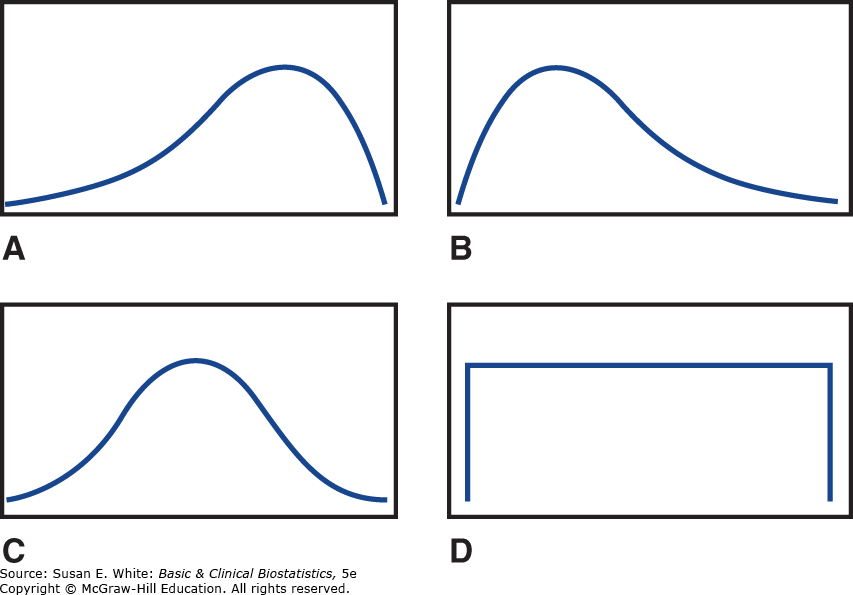
Hình 3-1. Hình dạng của các phân phối quan sát phổ biến. A: Lệch âm. B: Lệch dương. C và D: Đối xứng.
Những sự thật sau đây giúp chúng ta với tư cách là người đọc các bài báo biết được hình dạng của một phân phối mà không cần thực sự nhìn thấy nó.
- Nếu trung bình cộng và trung vị bằng nhau, phân phối của các quan sát là đối xứng, thường như trong Hình 3-1C và 3-1D.
- Nếu trung bình cộng lớn hơn trung vị, phân phối bị lệch phải, như trong Hình 3-1B.
- Nếu trung bình cộng nhỏ hơn trung vị, phân phối bị lệch trái, như trong Hình 3-1A.
Các hướng dẫn sau đây giúp chúng ta quyết định thước đo xu hướng trung tâm nào là tốt nhất.
- Trung bình cộng được sử dụng cho dữ liệu số lượng và cho các phân phối đối xứng (không lệch).
- Trung vị được sử dụng cho dữ liệu thứ tự hoặc cho dữ liệu số lượng nếu phân phối bị lệch nhiều.
- Yếu vị được sử dụng chủ yếu cho dữ liệu thứ tự và các phân phối số lượng có hai đỉnh.
- Trung bình nhân thường được sử dụng cho các quan sát được đo trên thang đo logarit hoặc dữ liệu có độ lệch vừa phải.
Các Thước đo Phân tán
Giả sử tất cả những gì bạn biết về 18 bệnh nhân được chọn ngẫu nhiên trong Vấn đề Tình huống 1 là trung bình cộng của điểm mức độ chủ động là 53.0. Mặc dù trung bình cộng cung cấp thông tin hữu ích, bạn sẽ có ý tưởng tốt hơn về sự phân phối của các điểm mức độ chủ động ở những bệnh nhân này nếu bạn biết điều gì đó về sự phân tán (spread), hay sự biến thiên (variation), của các quan sát. Một số thống kê được sử dụng để mô tả sự phân tán của dữ liệu: khoảng biến thiên (range), độ lệch chuẩn (standard deviation), hệ số biến thiên (coefficient of variation), thứ hạng phần trăm (percentile rank), và khoảng tứ phân vị (interquartile range). Tất cả sẽ được mô tả trong các phần sau.
Tính toán các Thước đo Phân tán
Khoảng biến thiên:
Khoảng biến thiên (range) là sự khác biệt giữa quan sát lớn nhất và nhỏ nhất. Nó rất dễ xác định sau khi dữ liệu đã được sắp xếp theo thứ tự. Ví dụ, điểm mức độ chủ động thấp nhất trong số 18 bệnh nhân là 34.7, và cao nhất là 75.3; do đó, khoảng biến thiên là 75.3 trừ 34.7, tức là 40.6. Nhiều tác giả cung cấp giá trị tối thiểu và tối đa thay vì khoảng biến thiên, và theo một số cách, những giá trị này hữu ích hơn.
Độ lệch chuẩn:
Độ lệch chuẩn (standard deviation) là thước đo phân tán được sử dụng phổ biến nhất với dữ liệu y tế và sức khỏe. Mặc dù ý nghĩa và cách tính toán của nó hơi phức tạp, nó rất quan trọng vì nó được sử dụng cả để mô tả cách các quan sát tập trung xung quanh trung bình cộng và trong nhiều kiểm định thống kê.
Hầu hết các bạn sẽ sử dụng máy tính để xác định độ lệch chuẩn, nhưng các bước liên quan đến việc tính toán của nó được trình bày để mang lại sự hiểu biết sâu hơn về ý nghĩa của thống kê này.
Độ lệch chuẩn là một thước đo về sự phân tán của dữ liệu xung quanh trung bình cộng của chúng. Nhìn sơ qua logic đằng sau thống kê này, chúng ta cần một thước đo về sự phân tán “trung bình” của các quan sát xung quanh trung bình cộng. Tại sao không tìm độ lệch của mỗi quan sát so với trung bình cộng, cộng các độ lệch này lại, và chia tổng cho n để tạo thành một sự tương tự với chính trung bình cộng? Vấn đề là tổng của các độ lệch xung quanh trung bình cộng luôn bằng không. Tại sao không sử dụng giá trị tuyệt đối của các độ lệch? Cách tiếp cận này tránh được vấn đề tổng bằng không, nhưng nó thiếu một số thuộc tính thống kê quan trọng, và do đó không được sử dụng. Thay vào đó, các độ lệch được bình phương trước khi cộng chúng lại, và sau đó căn bậc hai được tìm thấy để biểu thị độ lệch chuẩn trên thang đo lường ban đầu. Độ lệch chuẩn được ký hiệu là SD, sd, hoặc đơn giản là s (trong văn bản này chúng tôi sử dụng SD), và công thức của nó là:
Tên của thống kê trước khi lấy căn bậc hai là phương sai (variance), nhưng độ lệch chuẩn là thống kê được quan tâm chính vì nó được đo bằng cùng đơn vị với dữ liệu cơ bản (phương sai được đo bằng đơn vị bình phương).
Sử dụng thay vì trong mẫu số tạo ra một ước tính chính xác hơn (không chệch) về độ lệch chuẩn của quần thể thực và có các thuộc tính toán học mong muốn cho các suy luận thống kê.
Bây giờ chúng ta hãy thử một phép tính. Các giá trị điểm mức độ chủ động cho 18 bệnh nhân được lặp lại trong Bảng 3-3 cùng với các tính toán cần thiết. Các bước như sau:
- Đặt X là điểm mức độ chủ động cho mỗi bệnh nhân, và tìm trung bình cộng: trung bình cộng là 53.04.
- Trừ trung bình cộng khỏi mỗi quan sát để tạo thành các độ lệch .
- Bình phương mỗi độ lệch để tạo thành .
- Cộng các độ lệch bình phương lại. Tổng là 2354.14.
- Chia kết quả ở bước 4 cho (17), ta có 138.48. Giá trị này là phương sai.
- Lấy căn bậc hai của giá trị ở bước 5 để tìm độ lệch chuẩn; ta có 11.77.
Bảng 3-3. Tính toán độ lệch chuẩn của điểm mức độ chủ động trong một mẫu ngẫu nhiên 18 bệnh nhân.
| Bệnh nhân | X | ||
|---|---|---|---|
| 1 | 75.30 | 22.26 | 495.56 |
| 2 | 56.40 | 3.36 | 11.30 |
| 3 | 68.50 | 15.46 | 239.05 |
| 4 | 60.00 | 6.96 | 48.46 |
| 5 | 56.40 | 3.36 | 11.30 |
| 6 | 37.30 | -15.74 | 247.71 |
| 7 | 52.90 | -0.14 | 0.02 |
| 8 | 70.80 | 17.76 | 315.46 |
| 9 | 52.90 | -0.14 | 0.02 |
| 10 | 56.40 | 3.36 | 11.30 |
| 11 | 52.90 | -0.14 | 0.02 |
| 12 | 47.40 | -5.64 | 31.80 |
| 13 | 60.00 | 6.96 | 48.46 |
| 14 | 34.70 | -18.34 | 336.31 |
| 15 | 38.70 | -14.34 | 205.60 |
| 16 | 45.20 | -7.84 | 61.45 |
| 17 | 36.00 | -17.04 | 290.32 |
| 18 | 52.90 | -0.14 | 0.02 |
| Tổng | 954.70 | 0.00 | 2354.14 |
| Trung bình | 53.04 |
Dữ liệu từ Bos-Touwen I, và cộng sự (2015).
Độ lệch chuẩn, giống như trung bình cộng, là một thống kê rất quan trọng. Hai quy tắc kinh nghiệm khi sử dụng độ lệch chuẩn là:
- Bất kể các quan sát được phân phối như thế nào, ít nhất 75% các giá trị luôn nằm giữa hai con số này: trung bình cộng trừ 2 độ lệch chuẩn và trung bình cộng cộng 2 độ lệch chuẩn. Trong ví dụ về điểm mức độ chủ động, trung bình cộng là 53.0 và độ lệch chuẩn là 11.77; do đó, ít nhất 75% nằm giữa , hay giữa 29.50 và 76.57. Trong ví dụ này, tất cả 18 quan sát đều nằm trong giới hạn này.
- Nếu phân phối của các quan sát có hình chuông, thì có thể nói nhiều hơn về tỷ lệ phần trăm các quan sát nằm giữa trung bình cộng và độ lệch chuẩn. Đối với một phân phối hình chuông, xấp xỉ:
- 67% các quan sát nằm giữa trung bình cộng độ lệch chuẩn.
- 95% các quan sát nằm giữa trung bình cộng độ lệch chuẩn.
- 99.7% các quan sát nằm giữa trung bình cộng độ lệch chuẩn.
Hệ số biến thiên: Hệ số biến thiên (coefficient of variation – CV) là một thước đo hữu ích về sự phân tán tương đối trong dữ liệu. Nó được định nghĩa là độ lệch chuẩn chia cho trung bình cộng nhân với 100%. Nó tạo ra một thước đo về sự biến thiên tương đối—sự biến thiên so với kích thước của trung bình cộng. Công thức cho hệ số biến thiên là:
Ví dụ, nếu trung bình cộng và độ lệch chuẩn của điểm mức độ chủ động trong toàn bộ mẫu là 54.10 và 10.80, và đối với BMI là 27.55 và 4.58. CV cho điểm mức độ chủ động là , và CV cho BMI là . Do đó, chúng ta có thể kết luận rằng sự biến thiên tương đối trong điểm mức độ chủ động lớn hơn sự biến thiên trong BMI.
Phân vị: Một phân vị (percentile) là tỷ lệ phần trăm của một phân phối bằng hoặc thấp hơn một con số cụ thể. Ví dụ, hãy xem xét biểu đồ tăng trưởng thể chất tiêu chuẩn cho bé gái từ sơ sinh đến 36 tháng tuổi trong Hình 3-2. Đối với bé gái 21 tháng tuổi, phân vị thứ 95 của cân nặng là 12 kg. Điều này có nghĩa là trong số các bé gái 21 tháng tuổi, 95% có cân nặng từ 12 kg trở xuống và chỉ 5% có cân nặng hơn 12 kg. Phân vị thứ 50, tất nhiên, có cùng giá trị với trung vị; đối với bé gái 21 tháng tuổi, trung vị hoặc phân vị thứ 50 của cân nặng là khoảng 10.6 kg.
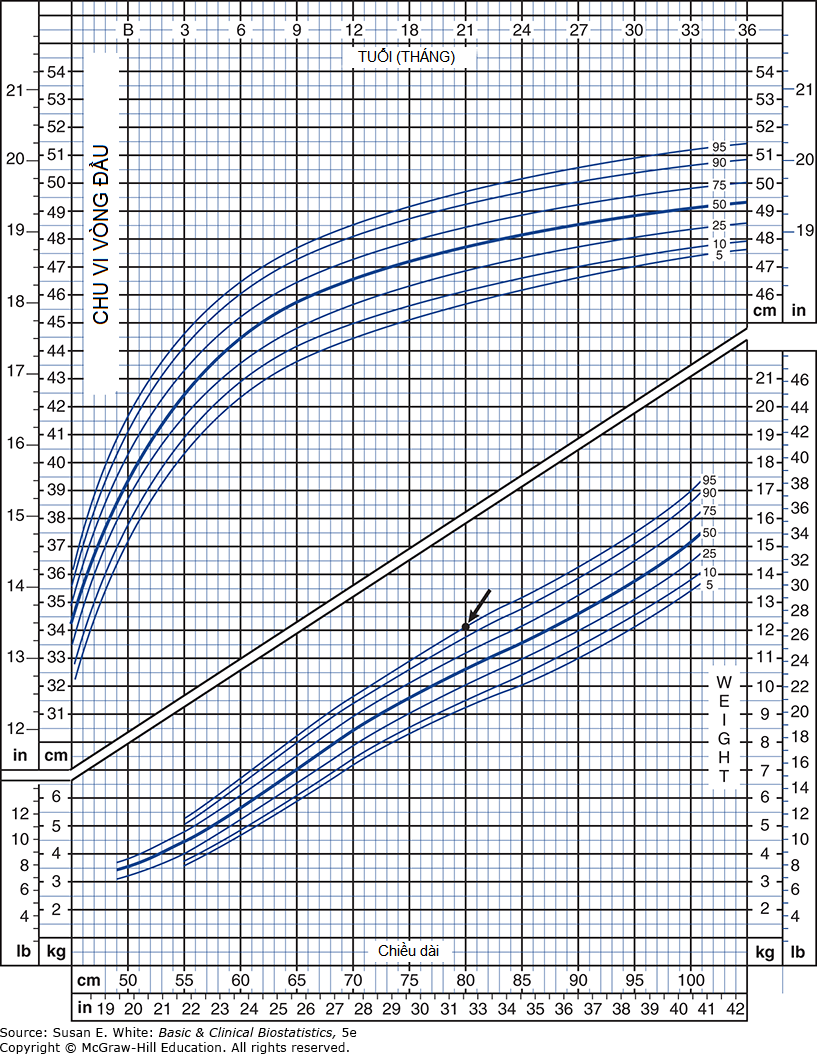
Hình 3-2. Biểu đồ tăng trưởng thể chất tiêu chuẩn. (Sao chép với sự cho phép của Trung tâm Thống kê Y tế Quốc gia phối hợp với Trung tâm Quốc gia Phòng chống Bệnh mãn tính và Nâng cao Sức khỏe (2000).)
Khoảng tứ phân vị:
Một thước đo biến thiên sử dụng các phân vị là khoảng tứ phân vị (interquartile range), được định nghĩa là sự khác biệt giữa phân vị thứ 25 và 75, còn được gọi là tứ phân vị thứ nhất (first quartile) và thứ ba (third quartile). Khoảng tứ phân vị chứa 50% quan sát ở giữa.
Sử dụng các Thước đo Phân tán Khác nhau:
- Độ lệch chuẩn được sử dụng khi trung bình cộng được sử dụng (tức là, với dữ liệu số lượng đối xứng).
- Phân vị và khoảng tứ phân vị được sử dụng trong hai tình huống: a. Khi trung vị được sử dụng (tức là, với dữ liệu thứ tự hoặc với dữ liệu số lượng bị lệch). b. Khi trung bình cộng được sử dụng nhưng mục tiêu là so sánh các quan sát cá nhân với một bộ tiêu chuẩn.
- Khoảng tứ phân vị được sử dụng để mô tả 50% trung tâm của một phân phối, bất kể hình dạng của nó.
- Khoảng biến thiên được sử dụng với dữ liệu số lượng khi mục đích là nhấn mạnh các giá trị cực đoan.
- Hệ số biến thiên được sử dụng khi mục đích là so sánh các phân phối được đo trên các thang đo khác nhau.
TRÌNH BÀY DỮ LIỆU SỐ LƯỢNG TRONG BẢNG VÀ ĐỒ THỊ
Dữ liệu số lượng có thể được trình bày theo nhiều cách khác nhau, và bộ dữ liệu liên quan đến Vấn đề Tình huống 1 về tự quản lý của bệnh nhân sẽ được sử dụng để minh họa chúng.
Biểu đồ Thân-Lá
Biểu đồ thân-lá (Stem-and-leaf plots) là các đồ thị cung cấp một phương tiện thuận tiện để kiểm đếm các quan sát và có thể được sử dụng như một cách hiển thị trực tiếp dữ liệu hoặc như một bước sơ bộ trong việc xây dựng một bảng tần suất. Dữ liệu báo cáo tuổi của các bệnh nhân trong nghiên cứu tự quản lý của bệnh nhân sẽ được sử dụng để minh họa một biểu đồ thân-lá.
Để tạo một biểu đồ thân-lá, vẽ một đường thẳng đứng, và đặt các chữ số đầu tiên của mỗi lớp—gọi là thân (stem)—ở bên trái của đường thẳng. Các con số ở bên phải của đường thẳng đứng đại diện cho chữ số thứ hai của mỗi quan sát; chúng là các lá (leaves). Bảng 3-4 và Bảng 3-5 minh họa quá trình xây dựng và kết quả cuối cùng. Biểu đồ vừa cung cấp một bản kiểm đếm các quan sát vừa cho thấy cách các độ tuổi được phân phối.
Bảng 3-4. Xây dựng biểu đồ thân-lá của điểm mức độ chủ động sử dụng các loại 5 điểm: Quan sát cho 10 đối tượng đầu tiên.
| Thân | Lá |
|---|---|
| 51 đến 55 | 2 |
| 56 đến 60 | 6, 7, 7 |
| 61 đến 65 | 1, 2, 4, 4 |
| 66 đến 70 | 5, 6, 8, 9 |
| 71 đến 75 | |
| 76 đến 80 | 6, 9 |
| 81 đến 85 | 0, 2, 4 |
| 86 đến 90 | |
| 91 đến 95 | 2 |
Dữ liệu từ Bos-Touwen I, và cộng sự (2015).
Bảng 3-5. Biểu đồ thân-lá của điểm mức độ chủ động sử dụng các loại 5 điểm.
Ghi chú: Điểm thập phân nằm ở bên phải của dấu | 1 chữ số.
| Thân (Điểm mức độ chủ động) | Lá |
|---|---|
| 2 | 4 |
| 2 | |
| 3 | 0124 |
| 3 | 55555566666666677777777777779999999999999999999999999999 |
| 4 | 00000000000000000000000000000222222222222222222222222222222222222222+68 |
| 4 | 555555555555555555555555555555555555555555555555555555555555555555555+212 |
| 5 | 333333333333333333333333333333333333333333333333333333333333333333333+50 |
| 5 | 666666666666666666666666666666666666666666666666666666666666+111 |
| 6 | 00000000000000000000000000000000000000000000000000000000000000000000+71 |
| 6 | 666666666666666666666666666666666666666699999999999999999999999999 |
| 7 | 1112233333333333333333333 |
| 7 | 55555555555555555555555588888888888888888888 |
| 8 | 000033333333 |
| 8 | 566666 |
| 9 | 2222222 |
| 9 | |
| 10 | 2 |
Dữ liệu từ Bos-Touwen I, Schuurmans M, Monninkhof EM, và cộng sự: Các đặc điểm của bệnh nhân và bệnh liên quan đến sự chủ động tự quản lý ở bệnh nhân đái tháo đường, bệnh phổi tắc nghẽn mãn tính, suy tim mãn tính và bệnh thận mãn tính: một nghiên cứu khảo sát cắt ngang, PLoS One. 2015 Tháng 5, 7;10(5):e0126400.
Bảng tần suất
Các tạp chí khoa học thường trình bày thông tin trong các phân phối tần suất (frequency distributions) hoặc bảng tần suất (frequency tables). Thang đo của các quan sát trước tiên phải được chia thành các lớp, như trong biểu đồ thân-lá. Sau đó, số lượng quan sát trong mỗi lớp được đếm. Bảng 3-6 là một ví dụ về bảng tần suất hiển thị điểm số cho bệnh nhân nam và nữ.
Bảng 3-6. Bảng tần suất cho điểm mức độ chủ động.
A. Điểm Mức độ Chủ động cho Bệnh nhân Nam
| Phân loại | Số Lượng | Số Lượng Tích Lũy | Tỷ Lệ % | Tỷ Lệ % Tích Lũy |
|---|---|---|---|---|
| 35 hoặc ít hơn | 7 | 7 | 1.01% | 1.01% |
| 35 đến 40 | 24 | 31 | 3.46% | 4.47% |
| 40 đến 45 | 88 | 119 | 12.68% | 17.15% |
| 45 đến 50 | 176 | 295 | 25.36% | 42.51% |
| 50 đến 55 | 76 | 371 | 10.95% | 53.46% |
| 55 đến 60 | 115 | 486 | 16.57% | 70.03% |
| 60 đến 65 | 92 | 578 | 13.26% | 83.29% |
| 65 đến 70 | 46 | 624 | 6.63% | 89.91% |
| 70 đến 75 | 25 | 649 | 3.60% | 93.52% |
| 75 đến 80 | 29 | 678 | 4.18% | 97.69% |
| 80 hoặc cao hơn | 16 | 694 | 2.31% | 100.00% |
B. Điểm Mức độ Chủ động cho Bệnh nhân Nữ
| Phân loại | Số Lượng | Số Lượng Tích Lũy | Tỷ Lệ % | Tỷ Lệ % Tích Lũy |
|---|---|---|---|---|
| 35 hoặc ít hơn | 4 | 4 | 0.87% | 0.87% |
| 35 đến 40 | 26 | 30 | 5.68% | 6.55% |
| 40 đến 45 | 59 | 89 | 12.88% | 19.43% |
| 45 đến 50 | 115 | 204 | 25.11% | 44.54% |
| 50 đến 55 | 54 | 258 | 11.79% | 56.33% |
| 55 đến 60 | 76 | 334 | 16.59% | 72.93% |
| 60 đến 65 | 59 | 393 | 12.88% | 85.81% |
| 65 đến 70 | 19 | 412 | 4.15% | 89.96% |
| 70 đến 75 | 25 | 437 | 5.46% | 95.41% |
| 75 đến 80 | 14 | 451 | 3.06% | 98.47% |
| 80 hoặc cao hơn | 7 | 458 | 1.53% | 100.00% |
Dữ liệu từ Bos-Touwen I, và cộng sự (2015).
Biểu đồ Cột, Biểu đồ Hộp, & Đa giác tần suất
Biểu đồ cột (Histograms): Một biểu đồ cột về tuổi trong nghiên cứu tự quản lý được hiển thị trong Hình 3-3. Biểu đồ cột thường trình bày thước đo quan tâm dọc theo trục X và số lượng hoặc tỷ lệ phần trăm các quan sát dọc theo trục Y.
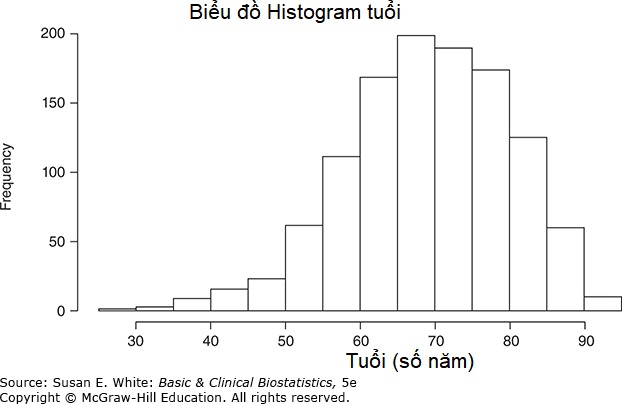
Hình 3-3. Biểu đồ cột về tuổi của bệnh nhân. (Dữ liệu từ Bos-Touwen I, và cộng sự, 2015).
Biểu đồ hộp (Box Plots): Một biểu đồ hộp (box plot), đôi khi được gọi là biểu đồ hộp-và-râu, là một cách khác để hiển thị thông tin khi mục tiêu là minh họa các vị trí nhất định trong phân phối. Một biểu đồ hộp về tuổi của các đối tượng được đưa ra trong Hình 3-4. Một hộp được vẽ với đỉnh ở tứ phân vị thứ ba và đáy ở tứ phân vị thứ nhất. Chiều dài của hộp là một biểu diễn trực quan của khoảng tứ phân vị, đại diện cho 50% dữ liệu ở giữa. Vị trí của trung vị được chỉ ra bằng một đường ngang trong hộp. Cuối cùng, các đường thẳng, hoặc râu (whiskers), kéo dài 1.5 lần khoảng tứ phân vị trên và dưới các phân vị thứ 75 và 25. Bất kỳ giá trị nào trên hoặc dưới râu được gọi là giá trị ngoại lai (outliers).
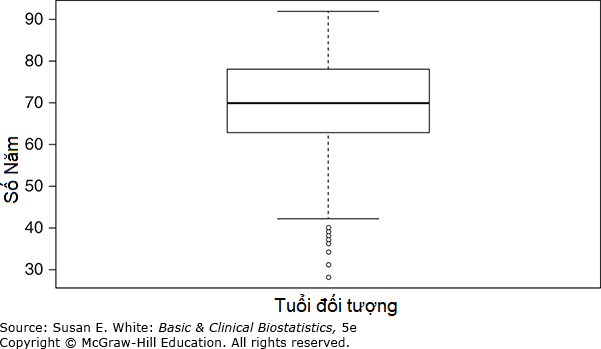
Hình 3-4. Biểu đồ hộp về tuổi của đối tượng. (Dữ liệu từ Bos-Touwen I, và cộng sự, 2015).
Đa giác tần suất (Frequency Polygons): Đa giác tần suất (Frequency polygons) là các đồ thị đường tương tự như biểu đồ cột và đặc biệt hữu ích khi so sánh hai phân phối trên cùng một đồ thị. Hình 3-5 là một biểu đồ cột dựa trên tần suất cho các bệnh nhân bị thuyên tắc phổi (PE) với một đa giác tần suất được chồng lên nó.
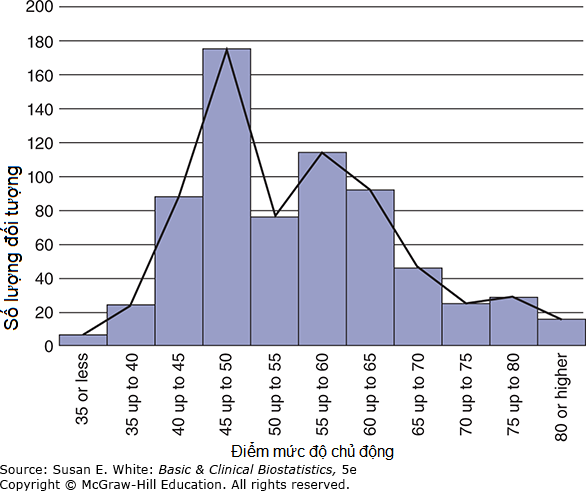
Hình 3-5. Đa giác tần suất của điểm mức độ chủ động cho bệnh nhân bị thuyên tắc phổi. (Dữ liệu từ Bos-Touwen I, và cộng sự, 2015).
Đồ thị So sánh Hai hoặc nhiều Nhóm: Biểu đồ hộp rất hiệu quả khi có nhiều hơn một nhóm và được hiển thị cho điểm mức độ chủ động giữa bệnh nhân nam và nữ trong Hình 3-6. Các đa giác tần suất phần trăm cũng hữu ích để so sánh hai phân phối tần suất, như minh họa trong Hình 3-7. Một loại đồ thị khác thường được sử dụng là biểu đồ thanh lỗi (error bar plot), như trong Hình 3-8.
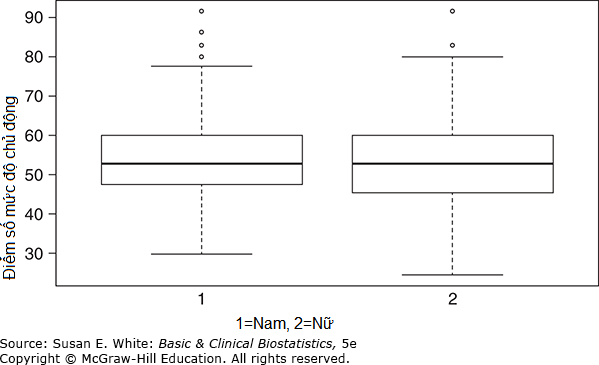
Hình 3-6. Biểu đồ hộp của điểm mức độ chủ động cho đối tượng nam và nữ. (Dữ liệu từ Bos-Touwen I, và cộng sự, 2015).
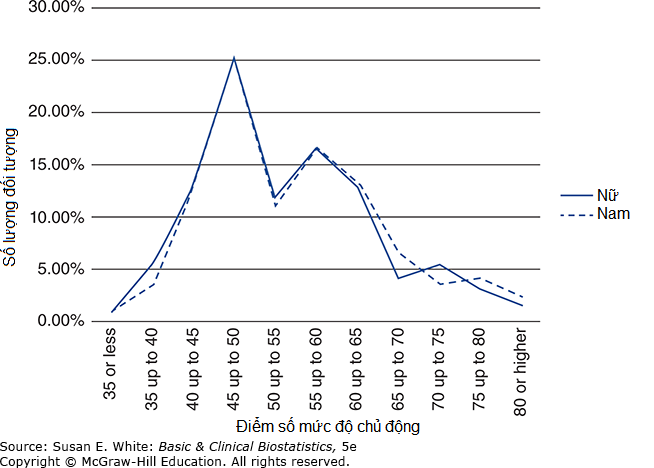
Hình 3-7. Đa giác tần suất của điểm mức độ chủ động cho bệnh nhân nam và nữ. (Dữ liệu từ Bos-Touwen I, và cộng sự, 2015).
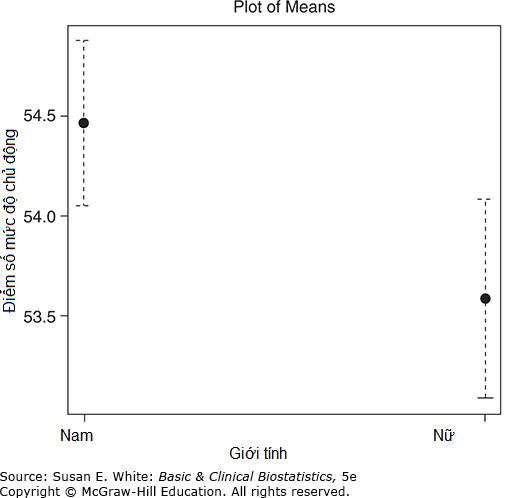
Hình 3-8. Biểu đồ thanh lỗi của điểm mức độ chủ động cho bệnh nhân nam và nữ. (Dữ liệu từ Bos-Touwen I, và cộng sự, 2015).
TÓM TẮT DỮ LIỆU DANH NGHĨA & THỨ TỰ BẰNG CÁC CON SỐ
Khi các quan sát được đo trên thang đo danh nghĩa, các phương pháp vừa thảo luận không phù hợp. Các đặc điểm được đo trên thang đo danh nghĩa không có giá trị số mà là số đếm hoặc tần suất xuất hiện.
Các cách Mô tả Dữ liệu Danh nghĩa
Dữ liệu danh nghĩa có thể được tóm tắt bằng nhiều phương pháp: tỷ lệ (proportions), phần trăm (percentages), tỷ số (ratios), và tỷ suất (rates). Để minh họa các thước đo này, chúng tôi sẽ sử dụng số lượng bệnh nhân được chẩn đoán mắc bệnh cúm dựa trên việc họ có tiêm vắc-xin cúm trong 12 tháng qua hay không; dữ liệu được đưa ra trong Bảng 3-7.
Bảng 3-7. Chẩn đoán cúm theo việc bệnh nhân có tiêm vắc-xin cúm trong 12 tháng qua hay không.
| Vắc-xin Cúm | Chẩn đoán Cúm: Có | Chẩn đoán Cúm: Không | Tổng |
|---|---|---|---|
| Có | 210 | 749 | 959 |
| Không | 1283 | 2327 | 3610 |
Dữ liệu từ Anderson KB, và cộng sự (2018).
Tỷ lệ và Phần trăm:
Một tỷ lệ (proportion) là số lượng, a, các quan sát có một đặc điểm nhất định chia cho tổng số quan sát, a + b, trong một nhóm nhất định. Một phần trăm (percentage) đơn giản là tỷ lệ nhân với 100%.
Tỷ số và Tỷ suất:
Một tỷ số (ratio) là số lượng quan sát trong một nhóm có một đặc điểm nhất định chia cho số lượng quan sát không có đặc điểm đó. Một tỷ suất (rate) tương tự như tỷ lệ ngoại trừ việc một số nhân (ví dụ: 1.000, 10.000, hoặc 100.000) được sử dụng, và chúng được tính toán trong một khoảng thời gian xác định.
Các Tỷ suất Thống kê Sinh tử
Các tỷ suất rất quan trọng trong dịch tễ học; chúng là cơ sở của việc tính toán thống kê sinh tử (vital statistics), mô tả tình trạng sức khỏe của các quần thể.
Tỷ suất tử vong (Mortality Rates): Cung cấp một cách tiêu chuẩn để so sánh số ca tử vong xảy ra ở các quần thể khác nhau. Tỷ suất thô (crude rate) là một tỷ suất được tính trên tất cả các cá nhân trong một quần thể nhất định. Bảng 3-8 cung cấp dữ liệu tử vong từ Thống kê Sinh tử của Hoa Kỳ.
Bảng 3-8. Số ca tử vong, tỷ suất tử vong, và tỷ suất tử vong hiệu chỉnh theo tuổi, theo chủng tộc và giới tính: Hoa Kỳ 2010-2016.
Bảng 3-8A. Số ca tử vong tại Hoa Kỳ: 2010-2016
| Năm | Toàn bộ | Nam | Nữ | Da trắng không phải gốc TBN (Toàn bộ) | Da trắng không phải gốc TBN (Nam) | Da trắng không phải gốc TBN (Nữ) | Da đen không phải gốc TBN (Toàn bộ) | Da đen không phải gốc TBN (Nam) | Da đen không phải gốc TBN (Nữ) |
|---|---|---|---|---|---|---|---|---|---|
| 2016 | 2,744,248 | 1,400,232 | 1,344,016 | 2,133,463 | 1,077,362 | 1,056,101 | 326,810 | 168,750 | 158,060 |
| 2015 | 2,712,630 | 1,373,404 | 1,339,226 | 2,123,631 | 1,063,705 | 1,059,926 | 315,254 | 161,850 | 153,404 |
| 2014 | 2,626,418 | 1,328,241 | 1,298,177 | 2,066,949 | 1,035,345 | 1,031,604 | 303,844 | 154,836 | 149,008 |
| 2013 | 2,596,993 | 1,306,034 | 1,290,959 | 2,052,660 | 1,021,135 | 1,031,525 | 299,227 | 152,661 | 146,566 |
| 2012 | 2,543,279 | 1,273,722 | 1,269,557 | 2,016,896 | 998,832 | 1,018,064 | 291,179 | 148,344 | 142,835 |
| 2011 | 2,515,458 | 1,254,978 | 1,260,480 | 2,006,319 | 989,835 | 1,016,484 | 286,797 | 145,052 | 141,745 |
| 2010 | 2,468,435 | 1,232,432 | 1,236,003 | 1,969,916 | 971,604 | 998,312 | 283,438 | 143,824 | 139,614 |
Bảng 3-8B. Tỷ suất tử vong tại Hoa Kỳ trên 100.000 dân: 2010-2016
| Năm | Toàn bộ | Nam | Nữ | Da trắng không phải gốc TBN (Toàn bộ) | Da trắng không phải gốc TBN (Nam) | Da trắng không phải gốc TBN (Nữ) | Da đen không phải gốc TBN (Toàn bộ) | Da đen không phải gốc TBN (Nam) | Da đen không phải gốc TBN (Nữ) |
|---|---|---|---|---|---|---|---|---|---|
| 2016 | 849.3 | 880.2 | 819.3 | 1059.7 | 1085.6 | 1034.6 | 775.5 | 836.2 | 719.7 |
| 2015 | 844.0 | 868.0 | 820.7 | 1055.3 | 1072.5 | 1038.5 | 754.6 | 809.4 | 704.3 |
| 2014 | 823.7 | 846.4 | 801.7 | 1028.1 | 1045.4 | 1011.3 | 735.4 | 783.3 | 691.4 |
| 2013 | 821.5 | 839.1 | 804.4 | 1021.6 | 1032.1 | 1011.5 | 733.4 | 782.5 | 688.4 |
| 2012 | 810.2 | 824.5 | 796.4 | 1004.9 | 1011.2 | 998.8 | 720.9 | 768.5 | 677.3 |
| 2011 | 807.3 | 818.7 | 796.3 | 1001.0 | 1004.1 | 998.1 | 718.0 | 760.4 | 679.2 |
| 2010 | 799.5 | 812.0 | 787.4 | 984.3 | 987.5 | 981.2 | 718.7 | 764.5 | 676.9 |
Bảng 3-8C. Tỷ suất tử vong hiệu chỉnh theo tuổi tại Hoa Kỳ trên 100.000 dân: 2010-2016
| Năm | Toàn bộ | Nam | Nữ | Da trắng không phải gốc TBN (Toàn bộ) | Da trắng không phải gốc TBN (Nam) | Da trắng không phải gốc TBN (Nữ) | Da đen không phải gốc TBN (Toàn bộ) | Da đen không phải gốc TBN (Nam) | Da đen không phải gốc TBN (Nữ) |
|---|---|---|---|---|---|---|---|---|---|
| 2016 | 728.8 | 861.0 | 617.5 | 749.0 | 879.5 | 637.2 | 882.8 | 1081.2 | 734.1 |
| 2015 | 733.1 | 863.2 | 624.2 | 753.2 | 881.3 | 644.1 | 876.1 | 1070.1 | 731.0 |
| 2014 | 724.6 | 855.1 | 616.7 | 742.8 | 872.3 | 633.8 | 870.7 | 1060.3 | 731.2 |
| 2013 | 731.9 | 863.6 | 623.5 | 747.1 | 876.8 | 638.4 | 885.2 | 1083.3 | 740.6 |
| 2012 | 732.8 | 865.1 | 624.7 | 745.8 | 876.2 | 637.6 | 887.1 | 1086.4 | 742.1 |
| 2011 | 741.3 | 875.3 | 632.4 | 754.3 | 887.2 | 644.6 | 901.6 | 1098.3 | 759.8 |
| 2010 | 747.0 | 887.1 | 634.9 | 755.0 | 892.5 | 643.3 | 920.4 | 1131.7 | 770.8 |
Nguồn: Xu JQ, Murphy SL, Kochanek KD, và cộng sự: Deaths: Final data for 2016. National Vital Statistics Reports; vol 67 no 5. Hyattsville, MD: National Center for Health Statistics. 2018.
Tỷ suất bệnh tật (Morbidity Rates): Tương tự như tỷ suất tử vong, nhưng nhiều nhà dịch tễ học cho rằng chúng cung cấp một thước đo trực tiếp hơn về tình trạng sức khỏe trong một quần thể.
Tỷ lệ hiện mắc (prevalence) và tỷ lệ mới mắc (incidence) là hai thước đo quan trọng thường được sử dụng. Tỷ lệ hiện mắc được định nghĩa là số cá nhân mắc một bệnh nhất định tại một thời điểm nhất định chia cho quần thể có nguy cơ mắc bệnh đó tại thời điểm đó. Tỷ lệ mới mắc được định nghĩa là số ca mắc mới đã xảy ra trong một khoảng thời gian nhất định chia cho quần thể có nguy cơ vào đầu khoảng thời gian đó.
Hiệu chỉnh Tỷ suất
Chúng ta chỉ có thể sử dụng các tỷ suất thô để so sánh giữa hai quần thể khác nhau nếu các quần thể đó tương tự nhau về mọi đặc điểm có thể ảnh hưởng đến tỷ suất. Nếu các quần thể khác nhau hoặc bị gây nhiễu bởi các yếu tố như tuổi, giới tính hoặc chủng tộc, thì phải sử dụng các tỷ suất đặc trưng theo tuổi, giới tính hoặc chủng tộc, hoặc các tỷ suất thô phải được hiệu chỉnh (adjusted); nếu không, các so sánh sẽ không hợp lệ. Các phương pháp hiệu chỉnh bao gồm phương pháp trực tiếp (direct method) và phương pháp gián tiếp (indirect method).
Bảng 3-9. Hiệu chỉnh tỷ suất tử vong trẻ sơ sinh: Phương pháp trực tiếp.
| Cân nặng lúc sinh | Quốc gia Phát triển | Quốc gia Đang phát triển | ||||
|---|---|---|---|---|---|---|
| Số trẻ sinh (N, nghìn) | Số ca tử vong | Tỷ suất | Số trẻ sinh (N, nghìn) | Số ca tử vong | Tỷ suất | |
| <1,500 g | 20 | 870 | 43.5 | 21 | 1,860 | 62.0 |
| 1,500-2,499 g | 30 | 480 | 16.0 | 45 | 900 | 20.0 |
| ≥2,500 g | 150 | 1,050 | 7.0 | 65 | 585 | 9.0 |
| Tổng | 200 | 2,400 | 12.0 | 140 | 3,345 | 23.9 |
Bảng 3-10. Hiệu chỉnh tỷ suất tử vong trẻ sơ sinh: Phương pháp gián tiếp.
| Cân nặng lúc sinh | Số trẻ sinh (nghìn) | Tỷ suất tử vong đặc trưng trên 1.000 trong Quần thể Chuẩn | |
|---|---|---|---|
| Quốc gia Phát triển | Quốc gia Đang phát triển | ||
| <1,500 g | 20 | 30 | 50.0 |
| 1,500-2,499 g | 30 | 45 | 20.0 |
| ≥2,500 g | 150 | 65 | 10.0 |
| Số ca tử vong | 2,400 | 3,345 |
BẢNG VÀ ĐỒ THỊ CHO DỮ LIỆU DANH NGHĨA VÀ THỨ TỰ
Cách đơn giản nhất để trình bày dữ liệu danh nghĩa là liệt kê các phạm trù trong một cột của bảng và tần suất (số đếm) hoặc tỷ lệ phần trăm các quan sát trong một cột khác. Khi hai đặc điểm trên thang đo danh nghĩa được kiểm tra, một cách phổ biến để hiển thị dữ liệu là trong một bảng ngẫu nhiên (contingency table). Đối với một hiển thị đồ họa của dữ liệu danh nghĩa hoặc thứ tự, biểu đồ cột (bar charts) thường được sử dụng. Hình 3-9 là một ví dụ.
Bảng 3-11. Dữ liệu về 28 bệnh nhân được chẩn đoán cúm A/H3 sau khi tiêm vắc-xin cúm trong 12 tháng qua.
| ID | Tuổi | Sốt | Ho | Đau họng | Khó thở |
|---|---|---|---|---|---|
| 1 | 70 | Có | Có | Không | Không |
| 2 | 70 | Có | Có | Có | Có |
| 3 | 75 | Có | Có | Có | Có |
| … | … | … | … | … | … |
| 28 | 69 | Có | Có | Có | Không |
Dữ liệu từ Anderson KB, và cộng sự (2018).
Bảng 3-12. Bảng tần suất đau họng ở bệnh nhân được chẩn đoán cúm A/H3 sau khi tiêm vắc-xin cúm trong 12 tháng qua.
| Đau họng | Số lượng Bệnh nhân |
|---|---|
| Có | 19 |
| Không | 9 |
Dữ liệu từ Anderson KB, và cộng sự (2018).
Bảng 3-13. Bước 1 trong việc xây dựng bảng ngẫu nhiên cho bệnh nhân có và không có đau họng và khó thở.
|
Phân loại |
Kiểm đếm |
|---|---|
| Đau họng và khó thở | /////////// |
| Đau họng không khó thở | //////// |
| Không đau họng và khó thở | ///// |
| Không đau họng không khó thở | //// |
Dữ liệu từ Anderson KB, và cộng sự (2018).
Bảng 3-14. Bảng ngẫu nhiên cho bệnh nhân có và không có đau họng và khó thở.
|
Đau họng |
Không khó thở | Khó thở |
|---|---|---|
| Không | 4 | 5 |
| Có | 8 | 11 |
Dữ liệu từ Anderson KB, và cộng sự (2018).

Hình 3-9. Minh họa một biểu đồ cột. (Dữ liệu từ Anderson KB, và cộng sự, 2018).
MÔ TẢ MỐI QUAN HỆ GIỮA HAI ĐẶC ĐIỂM
Phần lớn nghiên cứu trong y học liên quan đến mối quan hệ giữa hai hoặc nhiều đặc điểm.
Mối quan hệ giữa Hai Đặc điểm Số lượng
Hệ số tương quan (correlation coefficient) (đôi khi được gọi là hệ số tương quan momen tích Pearson) là một thước đo về mối quan hệ giữa hai đặc điểm số lượng. Hệ số tương quan luôn nằm trong khoảng từ -1 đến +1. Một hệ số tương quan bằng 0 có nghĩa là không có mối quan hệ tuyến tính nào tồn tại giữa hai biến. Hệ số xác định (coefficient of determination), , cho biết tỷ lệ phần trăm sự biến thiên của một biến có thể được giải thích bởi biến kia.
Bảng 3-15. Tính toán hệ số tương quan giữa điểm mức độ chủ động (X) và điểm SF-12 (Y) cho mẫu ngẫu nhiên bệnh nhân trong Vấn đề Tình huống 2.
| Bệnh nhân | X | Y | |||||
|---|---|---|---|---|---|---|---|
| 1 | 75.3 | 90.8 | 22.26 | 40.67 | 495.56 | 1654.15 | 905.39 |
| 2 | 56.4 | 54.6 | 3.36 | 4.42 | 11.30 | 19.55 | 14.86 |
| … | … | … | … | … | … | … | … |
| Tổng | 954.7 | 902.9 | 0.00 | 0.00 | 2354.14 | 12638.24 | 3749.89 |
| Trung bình | 53.0 | 50.2 |
Dữ liệu từ Bos-Touwen I, và cộng sự (2015).
Mối quan hệ giữa Hai Đặc điểm Thứ tự
Hệ số tương quan hạng Spearman (Spearman rank correlation), đôi khi được gọi là rho của Spearman, thường được sử dụng để mô tả mối quan hệ giữa hai đặc điểm thứ tự (hoặc một thứ tự và một số lượng).
Mối quan hệ giữa Hai Đặc điểm Danh nghĩa
Trong các nghiên cứu liên quan đến hai đặc điểm danh nghĩa, mối quan tâm chính có thể là độ lớn của mối quan hệ, chẳng hạn như mối quan hệ giữa một yếu tố nguy cơ và sự xuất hiện của một kết quả nhất định. Hai tỷ số được sử dụng để ước tính mối quan hệ như vậy là nguy cơ tương đối (relative risk) và tỷ số chênh (odds ratio).
Tỷ suất biến cố ở nhóm thực nghiệm (Experimental event rate – EER) là tỷ lệ những người có yếu tố nguy cơ mà mắc bệnh. Tỷ suất biến cố ở nhóm chứng (Control event rate – CER) là tỷ lệ những người không có yếu tố nguy cơ mà mắc bệnh.
Bảng 3-16. Sắp xếp bảng và công thức cho một số thước đo nguy cơ quan trọng.
| Thước đo | Công thức |
|---|---|
| Tỷ suất biến cố nhóm thực nghiệm (EER) | = A / (A + B) |
| Tỷ suất biến cố nhóm chứng (CER) | = C / (C + D) |
| Giảm nguy cơ tuyệt đối (ARR) | = |EER – CER| |
| Số bệnh nhân cần điều trị (NNT) | = 1 / ARR |
| Giảm nguy cơ tương đối (RRR) | = (|EER – CER|) / CER |
| Nguy cơ tương đối (RR) | = EER / CER |
| Tỷ số chênh (OR) | = (A/C) / (B/D) = AD / BC |
Nguy cơ tương đối (Relative Risk – RR) là tỷ số của tỷ lệ mới mắc ở những người có yếu tố nguy cơ so với tỷ lệ mới mắc ở những người không có yếu tố nguy cơ ().
Giảm nguy cơ tuyệt đối (Absolute Risk Reduction – ARR) là giá trị tuyệt đối của sự khác biệt giữa EER và CER.
Bảng 3-17. Tóm tắt chẩn đoán cúm theo tình trạng tiêm vắc-xin.
| Vắc-xin Cúm | Chẩn đoán Cúm: Có | Chẩn đoán Cúm: Không | Tổng |
|---|---|---|---|
| Có | (A) 210 | (B) 749 | 959 |
| Không | (C) 1,283 | (D) 2,327 | 3,610 |
| Tổng | 1,493 | 3,076 | 4,569 |
Dữ liệu từ Anderson KB, và cộng sự (2018).
Số bệnh nhân cần điều trị (Number Needed to Treat – NNT) là nghịch đảo của ARR (), cho biết số người cần được điều trị để ngăn ngừa một biến cố.
Tăng nguy cơ tuyệt đối (Absolute Risk Increase – ARI) được sử dụng khi một phương pháp điều trị làm tăng nguy cơ của một kết quả không mong muốn. Nghịch đảo của nó là Số bệnh nhân cần để gây hại (Number Needed to Harm – NNH).
Giảm nguy cơ tương đối (Relative Risk Reduction – RRR) là lượng giảm nguy cơ so với nguy cơ ban đầu ().
Tỷ số chênh (Odds Ratio – OR) được sử dụng trong các nghiên cứu bệnh-chứng. Đó là tỷ số của odds một người có kết quả bất lợi đã có nguy cơ so với odds một người không có kết quả bất lợi đã có nguy cơ.
Bảng 3-18. Tóm tắt việc sử dụng Benzodiazepine và tình trạng Alzheimer.
| Ca bệnh (mắc Alzheimer) (n=1,796) | Đối chứng (n=7,184) | Tỷ số chênh (95% CI) | |
|---|---|---|---|
| Đã từng sử dụng Benzodiazepine | 894 | 2,873 | 1.5 (1.4-1.7) |
| Liều Benzodiazepine hàng ngày | |||
| 1-90 | 234 | 1051 | 1.1 (0.9-1.3) |
| 91-180 | 70 | 257 | 1.3 (1.0-1.8) |
| >180 | 590 | 1565 | 1.8 (1.6-2.1) |
Dữ liệu từ Billioti de Gage S, và cộng sự (2014).
Bảng 3-19. Dữ liệu cho tỷ số chênh việc sử dụng benzodiazepine.
| Nhóm Benzodiazepine | Mắc Alzheimer | Không mắc Alzheimer | Tổng |
|---|---|---|---|
| Đã sử dụng | 894 | 2,873 | 3,767 |
| Chưa từng sử dụng | 902 | 4,311 | 5,213 |
| Tổng | 1,796 | 7,184 | 10,980 |
Dữ liệu từ Billioti de Gage S, và cộng sự (2014).
ĐỒ THỊ CHO HAI ĐẶC ĐIỂM
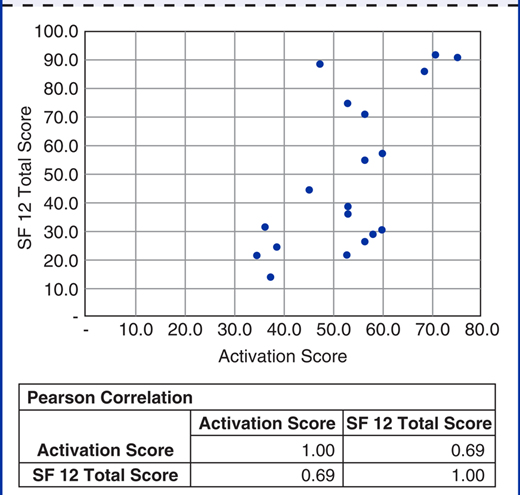
Các biểu đồ phân tán (scatterplots) thường được sử dụng để minh họa mối quan hệ giữa hai đặc điểm khi cả hai đều được đo trên thang đo số lượng. Hộp 3-1 chứa một biểu đồ phân tán về điểm mức độ chủ động và điểm tổng hợp SF-12.
| Hộp 3-1. MINH HỌA MỘT BIỂU ĐỒ PHÂN TÁN.
(Dữ liệu từ Bos-Touwen I, và cộng sự, 2015). Data from Bos-Touwen I, Schuurmans M, Monninkhof EM, et al: Patient and disease characteristics associated with activation for self-management in patients with diabetes, chronic obstructive pulmonary disease, chronic heart failure and chronic renal disease: a cross-sectional survey study, PLoS One. 2015 May 7;10(5):e0126400. |
CÁC LƯU Ý VỀ TRỰC QUAN HÓA DỮ LIỆU
Mục đích của việc trực quan hóa là trình bày kết quả một cách cho phép người đọc nắm bắt ngay thông điệp của bạn. Các thuộc tính như màu sắc, hình thức, chuyển động và vị trí không gian có thể được tận dụng để nâng cao thông điệp trong việc trực quan hóa dữ liệu. Các nguyên tắc chính bao gồm giữ cho hình ảnh đơn giản và rõ ràng, và chọn loại biểu đồ phù hợp để truyền đạt mối quan hệ hoặc sự biến thiên.
VÍ DỤ VỀ CÁC BIỂU ĐỒ VÀ ĐỒ THỊ GÂY HIỂU LẦM
Chất lượng của các biểu đồ và đồ thị được công bố trong y văn cao hơn so với các hiển thị tương tự trên báo chí phổ thông. Tuy nhiên, vẫn có những lỗi phổ biến. Việc biết về các lỗi phổ biến giúp bạn diễn giải thông tin một cách chính xác. Bốn lỗi thường gặp bao gồm:
- Lựa chọn thời điểm bắt đầu không phù hợp: Có thể làm cho một sự thay đổi trông ấn tượng hơn hoặc ít hơn bằng cách chọn thời điểm bắt đầu cho một đồ thị.
- Loại bỏ điểm gốc không (suppression of zero): Nếu trục Y không bắt đầu từ 0 và không được chỉ báo bằng một dấu ngắt, sự thay đổi có thể trông lớn hơn thực tế.
- Thay đổi tỷ lệ trên trục tung: Độ lớn của sự thay đổi có thể được tăng cường hoặc giảm thiểu bằng cách lựa chọn thang đo trên trục tung.
- Trình bày các tỷ lệ phần trăm không liên quan: Định dạng của bảng phải phản ánh các câu hỏi được đặt ra trong nghiên cứu.
Bảng 3-20. Ảnh hưởng của việc tính phần trăm theo cột so với phần trăm theo hàng cho nghiên cứu về tuân thủ thuốc và loại bảo hiểm.
A. Phần trăm dựa trên Mức độ Tuân thủ (Phần trăm theo Cột)
| Loại Bảo hiểm | Mức độ Tuân thủ | ||
|---|---|---|---|
| Thấp | Trung bình | Cao | |
| Medicaid | 30% | 20% | 15% |
| Medicare | 20% | 25% | 30% |
| Medicaid và Medicare | 5% | 5% | 5% |
| Bảo hiểm khác | 10% | 30% | 40% |
| Không có bảo hiểm | 35% | 20% | 10% |
B. Phần trăm dựa trên Loại Bảo hiểm (Phần trăm theo Hàng)
| Loại Bảo hiểm | Mức độ Tuân thủ | ||
|---|---|---|---|
| Thấp | Trung bình | Cao | |
| Medicaid | 45% | 30% | 25% |
| Medicare | 25% | 35% | 40% |
| Medicaid và Medicare | 33% | 33% | 33% |
| Bảo hiểm khác | 15% | 35% | 50% |
| Không có bảo hiểm | 55% | 30% | 15% |
TÓM TẮT
| Chương này trình bày hai khái niệm thống kê sinh học quan trọng: các thang đo lường khác nhau ảnh hưởng đến các phương pháp tóm tắt và hiển thị thông tin. Một số thước đo tóm tắt chúng tôi giới thiệu trong chương này tạo thành cơ sở của các kiểm định thống kê được minh họa trong các chương tiếp theo.
Mức độ đo lường đơn giản nhất là thang đo danh nghĩa, còn được gọi là thang đo phân loại hoặc định tính. Thang đo danh nghĩa đo lường các đặc điểm có thể được phân loại; số lượng quan sát trong mỗi loại được đếm. Tỷ lệ, tỷ số và phần trăm thường được sử dụng để tóm tắt dữ liệu phân loại. Các đặc điểm danh nghĩa được hiển thị trong các bảng ngẫu nhiên và biểu đồ cột. thang đo thứ bậc được sử dụng cho các đặc điểm có thứ tự cơ bản. Sự khác biệt giữa các giá trị trên thang đo không bằng nhau trong toàn bộ thang đo. Ví dụ là nhiều hệ thống phân giai đoạn bệnh, có bốn hoặc năm loại tương ứng với mức độ nghiêm trọng của bệnh. Trung vị, phân vị và khoảng biến thiên là các thước đo tóm tắt được lựa chọn vì chúng ít bị ảnh hưởng bởi các phép đo ngoại lai. Các đặc điểm thứ tự, giống như các đặc điểm danh nghĩa, được hiển thị trong các bảng ngẫu nhiên và biểu đồ cột. Thang đo số lượng là mức độ đo lường cao nhất; chúng còn được gọi là thang đo khoảng, tỷ lệ hoặc định lượng. Các đặc điểm được đo trên thang đo số lượng có thể là liên tục (nhận bất kỳ giá trị nào trên dòng số) hoặc rời rạc (chỉ nhận các giá trị nguyên). Trung bình cộng nên được sử dụng với các quan sát có phân phối đối xứng. Trung vị, cũng là một thước đo của điểm giữa, được sử dụng với các quan sát thứ tự hoặc các quan sát số lượng có phân phối lệch. Khi trung bình cộng phù hợp để mô tả điểm giữa, độ lệch chuẩn phù hợp để mô tả sự phân tán, hoặc biến thiên, của các quan sát. Giá trị của độ lệch chuẩn bị ảnh hưởng bởi các giá trị ngoại lai hoặc lệch, vì vậy phân vị hoặc khoảng tứ phân vị nên được sử dụng với các quan sát mà trung vị là phù hợp. Khoảng biến thiên cung cấp thông tin về các giá trị cực đoan, nhưng một mình nó không cung cấp cái nhìn sâu sắc về cách các quan sát được phân phối. Một cách dễ dàng để xác định xem phân phối của các quan sát là đối xứng hay lệch là tạo một biểu đồ cột hoặc biểu đồ hộp. Các phương pháp đồ họa khác bao gồm đa giác tần suất hoặc đồ thị đường, và biểu đồ thanh lỗi. Mặc dù mỗi phương pháp cung cấp thông tin về sự phân phối của các quan sát, biểu đồ hộp đặc biệt hữu ích như những hiển thị súc tích vì chúng cho thấy nhanh chóng sự phân phối của các giá trị. Biểu đồ thân-lá kết hợp các đặc điểm của bảng tần suất và biểu đồ cột; chúng cho thấy tần suất cũng như hình dạng của phân phối. Bảng tần suất tóm tắt các quan sát số lượng; thang đo được chia thành các lớp, và số lượng quan sát trong mỗi lớp được đếm. Cả tần suất và phần trăm đều được sử dụng phổ biến trong các bảng tần suất. Khi các phép đo bao gồm một đặc điểm danh nghĩa và một đặc điểm số lượng, đa giác tần suất, biểu đồ hộp và biểu đồ thanh lỗi minh họa sự phân phối của các quan sát số lượng cho mỗi giá trị của đặc điểm danh nghĩa. Hệ số tương quan chỉ ra mức độ của mối quan hệ tuyến tính giữa hai đặc điểm trên cùng một nhóm cá nhân. Tương quan hạng Spearman được sử dụng với các quan sát lệch hoặc thứ tự. Khi các đặc điểm được đo trên thang đo danh nghĩa và tỷ lệ được tính toán để mô tả chúng, nguy cơ tương đối hoặc tỷ số chênh có thể được sử dụng để đo lường mối quan hệ giữa hai đặc điểm. Dữ liệu từ nghiên cứu của Bos-Touwen và cộng sự (2015), Vấn đề Tình huống 2, đã được sử dụng để minh họa việc tính toán các thống kê phổ biến để tóm tắt dữ liệu, chẳng hạn như trung bình, trung vị và độ lệch chuẩn, và để cung cấp một số cách hữu ích để hiển thị dữ liệu trong đồ thị. Kết quả của nghiên cứu của Anderson và cộng sự (2018) về sàng lọc bạo lực gia đình (Vấn đề Tình huống 3) đã được sử dụng để minh họa rằng tỷ lệ và phần trăm có thể được sử dụng thay thế cho nhau để mô tả mối quan hệ của một phần với toàn bộ; tỷ số liên quan đến hai phần. Khi một tỷ lệ được tính toán theo thời gian, kết quả được gọi là một tỷ suất. Một số tỷ suất thường được sử dụng trong y học đã được định nghĩa và minh họa. Để so sánh các tỷ suất từ hai quần thể khác nhau, các quần thể phải tương tự nhau về các đặc điểm có thể ảnh hưởng đến tỷ suất; các tỷ suất đã hiệu chỉnh là cần thiết khi các đặc điểm này khác nhau giữa các quần thể. Trong y học, các tỷ suất thường được hiệu chỉnh cho sự chênh lệch về tuổi. Bảng ngẫu nhiên hiển thị hai đặc điểm danh nghĩa được đo trên cùng một tập hợp các đối tượng. Biểu đồ cột là một cách hiệu quả để minh họa dữ liệu danh nghĩa. |
BÀI TẬP
- Chứng minh rằng tổng của các độ lệch so với trung bình bằng 0. Hãy chứng minh thực tế này bằng cách tìm tổng của các độ lệch cho sự biến thiên của điểm mức độ chủ động trong Bảng 3-3.
- Bos-Touwen và cộng sự đã phân tích dữ liệu điểm SF-12 từ 1.154 bệnh nhân. Sử dụng bộ dữ liệu, hãy hoàn thành τα sau: a. Tính trung bình và độ lệch chuẩn của Điểm Tổng hợp SF-12 (SF12_total_score). b. Tạo một bảng tần suất của SF12_total_score cho bệnh nhân sử dụng các loại sau: 0 đến 20, 21 đến 40, 41 đến 60, 61 đến 80, 81 đến 100. c. Tạo biểu đồ hộp của SF12_total_score theo giới tính.
- Một lần nữa, sử dụng bộ dữ liệu Bos-Touwen, tạo một bảng tần suất của trung bình, trung vị, tối thiểu và tối đa của SF12_total_score cho bệnh nhân trong các loại tuổi.
- Sử dụng dữ liệu từ nghiên cứu của Anderson để tạo một bảng ngẫu nhiên 2×2 cho tần suất chẩn đoán cúm (Flu_final_posneg) trong các cột và nơi bệnh nhân đến khám (Collection_site). Sau khi bạn đã tìm thấy các con số trong các ô, hãy sử dụng chương trình R Commander để tìm tỷ số chênh.
- Hình dạng có khả năng nhất của phân phối các quan sát trong các nghiên cứu sau là gì? a. Tuổi của các đối tượng trong một nghiên cứu về bệnh nhân mắc bệnh Crohn. b. Số trẻ sơ sinh được đỡ đẻ bởi tất cả các bác sĩ đã đỡ đẻ trong một thành phố lớn trong năm qua. c. Số bệnh nhân được chuyển đến một bệnh viện tuyến trên bởi các bệnh viện khác trong khu vực.
- Vẽ các đa giác tần suất để so sánh điểm Tổng hợp SF-12 của nam và nữ trong nghiên cứu của Bos-Touwen và cộng sự (2015). Bạn kết luận điều gì?
- Công thức tính toán cho độ lệch chuẩn là: Minh họa rằng giá trị của độ lệch chuẩn được tính từ công thức này tương đương với giá trị được tìm thấy bằng công thức định nghĩa sử dụng dữ liệu chỉ số sốc trong Bảng 3-3.
- Các thước đo xu hướng trung tâm và phân tán nào là phù hợp nhất để sử dụng với các bộ dữ liệu sau? a. Lương của 125 bác sĩ trong một phòng khám. b. Điểm thi của tất cả sinh viên y khoa tham gia Kỳ thi USMLE Bước I của Hội đồng Quốc gia trong một năm nhất định. c. Nồng độ natri huyết thanh của những người khỏe mạnh. d. Số khớp đau trong 30 khớp được đánh giá trong một cuộc kiểm tra tiêu chuẩn về hoạt động bệnh ở bệnh nhân viêm khớp dạng thấp. e. Sự hiện diện của tiêu chảy ở một nhóm trẻ sơ sinh. f. Các giai đoạn bệnh của một nhóm bệnh nhân mắc hội chứng Reye (sáu giai đoạn, từ 0 = tỉnh táo đến 5 = không thể đánh thức, liệt mềm, mất phản xạ, đồng tử không phản ứng). g. Tuổi khởi phát ung thư vú ở nữ giới. h. Số viên thuốc còn lại trong lọ thuốc của đối tượng khi các nhà điều tra trong một nghiên cứu đếm số viên thuốc để đánh giá sự tuân thủ trong việc dùng thuốc.
- Hệ số tương quan giữa điểm mức độ chủ động và điểm tổng hợp SF-12 là 0.27 (Bos-Touwen và cộng sự, 2015) và giữa tuổi và điểm tổng hợp SF-12 là -0.19. Bạn diễn giải những giá trị này như thế nào?
- Tham khảo Hình 3-2 để trả lời các câu hỏi sau: a. Cân nặng trung bình của bé gái 24 tháng tuổi là bao nhiêu? b. Phân vị thứ 90 cho chu vi vòng đầu của bé gái 12 tháng tuổi là bao nhiêu? c. Phân vị thứ năm về cân nặng của bé gái 12 tháng tuổi là bao nhiêu?
- Tìm hệ số biến thiên của sự thay đổi trung bình trong điểm mức độ chủ động cho nam và nữ sử dụng dữ liệu từ Bos-Touwen và cộng sự (2015). Có giới tính nào có sự biến thiên tương đối lớn hơn trong điểm mức độ chủ động không?
- Từ kinh nghiệm của chính họ tại một bệnh viện công ở thành thị, Kaku và Lowenstein (1990) đã ghi nhận rằng đột quỵ liên quan đến việc sử dụng ma túy giải trí đang xảy ra thường xuyên hơn ở những người trẻ tuổi. Để điều tra vấn đề, họ đã xác định tất cả các bệnh nhân từ 15 đến 44 tuổi được nhập viện tại một bệnh viện nhất định và chọn các đối chứng được ghép cặp theo giới tính và tuổi từ các bệnh nhân nhập viện với các tình trạng y tế hoặc phẫu thuật cấp tính mà việc lạm dụng ma túy giải trí chưa được chứng minh là một yếu tố nguy cơ. Dữ liệu được đưa ra trong Bảng 3-21. Tỷ số chênh là bao nhiêu?
Bảng 3-21. Dữ liệu cho tỷ số chênh đột quỵ với tiền sử lạm dụng thuốc.
| Đột quỵ | Đối chứng | |
|---|---|---|
| Lạm dụng thuốc | 73 | 18 |
| Không lạm dụng thuốc | 141 | 196 |
| Tổng | 214 | 214 |
Dữ liệu từ Kaku DA, Lowenstein DH (1990).
- Bài tập nhóm. Lấy một bản sao của nghiên cứu của Moore và cộng sự (1991) từ thư viện y khoa của bạn và trả lời các câu hỏi sau: a. Mục đích của nghiên cứu này là gì? b. Thiết kế nghiên cứu là gì? c. Tại sao hai nhóm bệnh nhân được sử dụng trong nghiên cứu? d. Kiểm tra các biểu đồ hộp trong Hình 3-1 của bài báo. Có thể rút ra kết luận gì từ các biểu đồ? e. Kiểm tra các biểu đồ hộp trong Hình 3-2 của bài báo. Các biểu đồ này cho bạn biết điều gì về mức độ pH ở những người đàn ông khỏe mạnh bình thường?
- Bài tập nhóm. Điều quan trọng là các thang đo được khuyến nghị cho các bác sĩ sử dụng trong việc đánh giá nguy cơ hoặc đưa ra quyết định quản lý phải được chứng minh là đáng tin cậy và hợp lệ. Chọn một lĩnh vực quan tâm và tham khảo một số bài báo tạp chí mô tả các thang đo hoặc quy tắc quyết định. Đánh giá xem các tác giả có trình bày đủ bằng chứng về khả năng tái lập và tính hợp lệ của các thang đo này không. Loại khả năng tái lập nào đã được thiết lập? Loại tính hợp lệ nào? Những điều này có đủ để đảm bảo việc sử dụng thang đo không?
Bảng chú giải thuật ngữ Anh-Việt: Chương 3
| STT | Thuật ngữ tiếng Anh | Phiên âm IPA | Nghĩa Tiếng Việt |
|---|---|---|---|
| 1 | Scale of measurement | /skeɪl əv ˈmɛʒərmənt/ | Thang đo lường |
| 2 | Summarized | /ˈsʌməˌraɪzd/ | Được tóm tắt |
| 3 | Displayed | /dɪˈspleɪd/ | Được trình bày/hiển thị |
| 4 | Analyzed | /ˈænəˌlaɪzd/ | Được phân tích |
| 5 | Nominal scales | /ˈnɒmɪnəl skeɪlz/ | Thang đo danh nghĩa |
| 6 | Discrete characteristics | /dɪˈskriːt ˌkærəktəˈrɪstɪks/ | Đặc điểm rời rạc |
| 7 | Ordinal scales | /ˈɔːrdɪnəl skeɪlz/ | Thang đo thứ bậc |
| 8 | Inherent order | /ɪnˈhɪərənt ˈɔːrdər/ | Trật tự sẵn có |
| 9 | Numerical scales | /njuːˈmɛrɪkəl skeɪlz/ | Thang đo số lượng |
| 10 | Means | /miːnz/ | Giá trị trung bình |
| 11 | Distribution | /ˌdɪstrɪˈbjuːʃən/ | Phân phối |
| 12 | Numerical characteristic | /njuːˈmɛrɪkəl ˌkærəktəˈrɪstɪk/ | Đặc điểm số lượng |
| 13 | Medians | /ˈmiːdiənz/ | Giá trị trung vị |
| 14 | Ordinal characteristic | /ˈɔːrdɪnəl ˌkærəktəˈrɪstɪk/ | Đặc điểm thứ bậc |
| 15 | Skewed | /skjuːd/ | Bị lệch |
| 16 | Standard deviation | /ˈstændərd ˌdiːviˈeɪʃən/ | Độ lệch chuẩn |
| 17 | Spread | /sprɛd/ | Sự phân tán |
| 18 | Observations | /ˌɒbzərˈveɪʃənz/ | Các quan sát |
| 19 | Coefficient of variation | /ˌkoʊɪˈfɪʃənt əv ˌvɛəriˈeɪʃən/ | Hệ số biến thiên |
| 20 | Relative spread | /ˈrɛlətɪv sprɛd/ | Sự phân tán tương đối |
| 21 | Percentiles | /pərˈsɛntaɪlz/ | Phân vị |
| 22 | Norm | /nɔːrm/ | Chuẩn, giá trị bình thường |
| 23 | Stem-and-leaf plots | /stɛm ænd liːf plɒts/ | Biểu đồ thân-lá |
| 24 | Frequency tables | /ˈfriːkwənsi ˈteɪbəlz/ | Bảng tần suất |
| 25 | Histograms | /ˈhɪstəˌɡræmz/ | Biểu đồ cột (biểu đồ tần suất) |
| 26 | Box plots | /bɒks plɒts/ | Biểu đồ hộp |
| 27 | Frequency polygons | /ˈfriːkwənsi ˈpɒlɪɡənz/ | Đa giác tần suất |
| 28 | Proportions | /prəˈpɔːrʃənz/ | Tỷ lệ |
| 29 | Percentages | /pərˈsɛntɪdʒɪz/ | Tỷ lệ phần trăm |
| 30 | Rates | /reɪts/ | Tỷ suất |
| 31 | Prevalence | /ˈprɛvələns/ | Tỷ lệ hiện mắc |
| 32 | Incidence | /ˈɪnsɪdəns/ | Tỷ lệ mới mắc |
| 33 | Morbidity | /mɔːrˈbɪdɪti/ | Tình trạng bệnh tật |
| 34 | Confounding factor | /kənˈfaʊndɪŋ ˈfæktər/ | Yếu tố gây nhiễu |
| 35 | Correlation | /ˌkɒrəˈleɪʃən/ | Tương quan |
| 36 | Risk ratio | /rɪsk ˈreɪʃioʊ/ | Tỷ số nguy cơ (Nguy cơ tương đối) |
| 37 | Odds ratio | /ɒdz ˈreɪʃioʊ/ | Tỷ số chênh |
| 38 | Event rates | /ɪˈvɛnt reɪts/ | Tỷ suất biến cố |
| 39 | Number needed to treat | /ˈnʌmbər ˈniːdɪd tu triːt/ | Số bệnh nhân cần điều trị (NNT) |
| 40 | Scatterplots | /ˈskætərplɒts/ | Biểu đồ phân tán |
| 41 | Descriptive statistics | /dɪˈskrɪptɪv stəˈtɪstɪks/ | Thống kê mô tả |
| 42 | Categories | /ˈkætɪɡəriz/ | Các phạm trù, các nhóm |
| 43 | Attribute | /ˈætrɪˌbjuːt/ | Thuộc tính |
| 44 | Dichotomous | /daɪˈkɒtəməs/ | Nhị phân, nhị phân hóa |
| 45 | Binary | /ˈbaɪnəri/ | Nhị phân |
| 46 | Qualitative observations | /ˈkwɒlɪtətɪv ˌɒbzərˈveɪʃənz/ | Quan sát định tính |
| 47 | Categorical observations | /ˌkætɪˈɡɒrɪkəl ˌɒbzərˈveɪʃənz/ | Quan sát theo phạm trù |
| 48 | Contingency tables | /kənˈtɪndʒənsi ˈteɪbəlz/ | Bảng ngẫu nhiên (bảng chéo) |
| 49 | Bar charts | /bɑːr tʃɑːrts/ | Biểu đồ cột |
| 50 | Staged | /steɪdʒd/ | Được phân giai đoạn |
| 51 | Prognosis | /prɒɡˈnoʊsɪs/ | Tiên lượng |
| 52 | Rank-order scale | /ræŋk ˈɔːrdər skeɪl/ | Thang đo xếp hạng |
| 53 | Quantitative observations | /ˈkwɒntɪtətɪv ˌɒbzərˈveɪʃənz/ | Quan sát định lượng |
| 54 | Continuous scale | /kənˈtɪnjuəs skeɪl/ | Thang đo liên tục |
| 55 | Discrete scale | /dɪˈskriːt skeɪl/ | Thang đo rời rạc |
| 56 | Integers | /ˈɪntɪdʒərz/ | Số nguyên |
| 57 | Central tendency | /ˈsɛntrəl ˈtɛndənsi/ | Xu hướng trung tâm |
| 58 | Arithmetic mean | /əˈrɪθmətɪk miːn/ | Trung bình cộng số học |
| 59 | Sum | /sʌm/ | Tổng |
| 60 | Random sampling | /ˈrændəm ˈsæmplɪŋ/ | Lấy mẫu ngẫu nhiên |
| 61 | Extreme values | /ɪkˈstriːm ˈvæljuːz/ | Giá trị cực đoan |
| 62 | Weighted average | /ˈweɪtɪd ˈævərɪdʒ/ | Trung bình có trọng số |
| 63 | Raw numbers | /rɔː ˈnʌmbərz/ | Số liệu thô |
| 64 | Rank order | /ræŋk ˈɔːrdər/ | Thứ tự xếp hạng |
| 65 | Mode | /moʊd/ | Yếu vị |
| 66 | Bimodal | /baɪˈmoʊdəl/ | Phân phối hai đỉnh |
| 67 | Modal class | /ˈmoʊdəl klæs/ | Lớp yếu vị |
| 68 | Geometric mean | /ˌdʒiːəˈmɛtrɪk miːn/ | Trung bình nhân |
| 69 | Logarithm | /ˈlɒɡəˌrɪðəm/ | Logarit |
| 70 | Symmetric distribution | /sɪˈmɛtrɪk ˌdɪstrɪˈbjuːʃən/ | Phân phối đối xứng |
| 71 | Skewed distribution | /skjuːd ˌdɪstrɪˈbjuːʃən/ | Phân phối lệch |
| 72 | Negatively skewed | /ˈnɛɡətɪvli skjuːd/ | Lệch âm (lệch trái) |
| 73 | Positively skewed | /ˈpɒzɪtɪvli skjuːd/ | Lệch dương (lệch phải) |
| 74 | Variation | /ˌvɛəriˈeɪʃən/ | Sự biến thiên |
| 75 | Dispersion | /dɪˈspɜːrʃən/ | Sự phân tán |
| 76 | Range | /reɪndʒ/ | Khoảng biến thiên |
| 77 | Minimum value | /ˈmɪnɪməm ˈvæljuː/ | Giá trị tối thiểu |
| 78 | Maximum value | /ˈmæksɪməm ˈvæljuː/ | Giá trị tối đa |
| 79 | Deviation | /ˌdiːviˈeɪʃən/ | Độ lệch |
| 80 | Absolute value | /ˈæbsəluːt ˈvæljuː/ | Giá trị tuyệt đối |
| 81 | Squared deviations | /skwɛərd ˌdiːviˈeɪʃənz/ | Độ lệch bình phương |
| 82 | Square root | /skwɛər ruːt/ | Căn bậc hai |
| 83 | Variance | /ˈvɛəriəns/ | Phương sai |
| 84 | Unbiased estimate | /ʌnˈbaɪəst ˈɛstɪmət/ | Ước lượng không chệch |
| 85 | Definitional formula | /ˌdɛfɪˈnɪʃənəl ˈfɔːrmjələ/ | Công thức định nghĩa |
| 86 | Computational formula | /ˌkɒmpjuˈteɪʃənəl ˈfɔːrmjələ/ | Công thức tính toán |
| 87 | Bell-shaped distribution | /bɛl ʃeɪpt ˌdɪstrɪˈbjuːʃən/ | Phân phối hình chuông |
| 88 | Quality control | /ˈkwɒlɪti kənˈtroʊl/ | Kiểm soát chất lượng |
| 89 | Quartiles | /ˈkwɔːrtaɪlz/ | Tứ phân vị |
| 90 | Interquartile range | /ˌɪntərˈkwɔːrtaɪl reɪndʒ/ | Khoảng tứ phân vị |
| 91 | Classes | /ˈklæsɪz/ | Các lớp |
| 92 | Intervals | /ˈɪntərvəlz/ | Các khoảng |
| 93 | Stem | /stɛm/ | Thân |
| 94 | Leaves | /liːvz/ | Lá |
| 95 | Class width | /klæs wɪdθ/ | Độ rộng lớp |
| 96 | Open-ended intervals | /ˈoʊpən ˈɛndɪd ˈɪntərvəlz/ | Khoảng mở |
| 97 | Class limits | /klæs ˈlɪmɪts/ | Giới hạn lớp |
| 98 | Midpoint | /ˈmɪdˌpɔɪnt/ | Trung điểm |
| 99 | Tally | /ˈtæli/ | Kiểm đếm |
| 100 | Cumulative frequencies | /ˈkjuːmjələtɪv ˈfriːkwənsiz/ | Tần suất tích lũy |
| 101 | Error bar plot | /ˈɛrər bɑːr plɒt/ | Biểu đồ thanh lỗi |
| 102 | Standard error | /ˈstændərd ˈɛrər/ | Sai số chuẩn |
| 103 | Ratios | /ˈreɪʃioʊz/ | Tỷ số |
| 104 | Base (multiplier) | /beɪs (ˈmʌltɪˌplaɪər)/ | Cơ số (hệ số nhân) |
| 105 | Vital statistics | /ˈvaɪtəl stəˈtɪstɪks/ | Thống kê sinh tử |
| 106 | Mortality rates | /mɔːrˈtæləti reɪts/ | Tỷ suất tử vong |
| 107 | Numerator | /ˈnjuːməˌreɪtər/ | Tử số |
| 108 | Denominator | /dɪˈnɒmɪˌneɪtər/ | Mẫu số |
| 109 | Crude rate | /kruːd reɪt/ | Tỷ suất thô |
| 110 | Sex-specific mortality rate | /sɛks spəˈsɪfɪk mɔːrˈtæləti reɪt/ | Tỷ suất tử vong theo giới |
| 111 | Age-adjusted rates | /eɪdʒ əˈdʒʌstɪd reɪts/ | Tỷ suất hiệu chỉnh theo tuổi |
| 112 | Cause-specific mortality rates | /kɔːz spəˈsɪfɪk mɔːrˈtæləti reɪts/ | Tỷ suất tử vong theo nguyên nhân |
| 113 | Infant mortality rate | /ˈɪnfənt mɔːrˈtæləti reɪt/ | Tỷ suất tử vong trẻ sơ sinh |
| 114 | Case fatality rate | /keɪs feɪˈtæləti reɪt/ | Tỷ suất tử vong trên ca bệnh |
| 115 | Morbidity rates | /mɔːrˈbɪdɪti reɪts/ | Tỷ suất bệnh tật |
| 116 | Population at risk | /ˌpɒpjuˈleɪʃən ət rɪsk/ | Quần thể có nguy cơ |
| 117 | Adjusted rates | /əˈdʒʌstɪd reɪts/ | Tỷ suất đã hiệu chỉnh |
| 118 | Direct method | /dɪˈrɛkt ˈmɛθəd/ | Phương pháp trực tiếp |
| 119 | Reference population | /ˈrɛfərəns ˌpɒpjuˈleɪʃən/ | Quần thể tham chiếu |
| 120 | Rate standardization | /reɪt ˌstændərdaɪˈzeɪʃən/ | Chuẩn hóa tỷ suất |
| 121 | Indirect method | /ˌɪndɪˈrɛkt ˈmɛθəd/ | Phương pháp gián tiếp |
| 122 | Standardized mortality ratio | /ˈstændərdaɪzd mɔːrˈtæləti ˈreɪʃioʊ/ | Tỷ số tử vong chuẩn hóa (SMR) |
| 123 | Observed deaths | /əbˈzɜːrvd dɛθs/ | Số ca tử vong quan sát được |
| 124 | Expected deaths | /ɪkˈspɛktɪd dɛθs/ | Số ca tử vong kỳ vọng |
| 125 | Pie charts | /paɪ tʃɑːrts/ | Biểu đồ tròn |
| 126 | Pictographs | /ˈpɪktəˌɡræfs/ | Biểu đồ hình ảnh |
| 127 | Pearson product moment correlation coefficient | /ˈpɪərsən ˈprɒdʌkt ˈmoʊmənt ˌkɒrəˈleɪʃən ˌkoʊɪˈfɪʃənt/ | Hệ số tương quan momen tích Pearson |
| 128 | Correlation coefficient | /ˌkɒrəˈleɪʃən ˌkoʊɪˈfɪʃənt/ | Hệ số tương quan |
| 129 | Coefficient of determination | /ˌkoʊɪˈfɪʃənt əv dɪˌtɜːrmɪˈneɪʃən/ | Hệ số xác định (R-bình phương) |
| 130 | Linear relationship | /ˈlɪniər rɪˈleɪʃənʃɪp/ | Mối quan hệ tuyến tính |
| 131 | Outlying values | /aʊtˈlaɪɪŋ ˈvæljuːz/ | Giá trị ngoại lai |
| 132 | Transformation of the data | /ˌtrænsfərˈmeɪʃən əv ðə ˈdeɪtə/ | Phép biến đổi dữ liệu |
| 133 | Spearman rank correlation | /ˈspɪərmən ræŋk ˌkɒrəˈleɪʃən/ | Tương quan hạng Spearman |
| 134 | Curvilinear relationship | /ˌkɜːrvɪˈlɪniər rɪˈleɪʃənʃɪp/ | Mối quan hệ đường cong |
| 135 | Causation | /kɔːˈzeɪʃən/ | Quan hệ nhân quả |
| 136 | Spearman’s rho | /ˈspɪərmənz roʊ/ | Rho của Spearman |
| 137 | Rank-ordering | /ræŋk ˈɔːrdərɪŋ/ | Xếp hạng |
| 138 | Ties (in ranks) | /taɪz (ɪn ræŋks)/ | Các hạng bằng nhau (trùng hạng) |
| 139 | Relative risk | /ˈrɛlətɪv rɪsk/ | Nguy cơ tương đối (RR) |
| 140 | Experimental event rate (EER) | /ɪkˌspɛrɪˈmɛntəl ɪˈvɛnt reɪt/ | Tỷ suất biến cố nhóm thực nghiệm |
| 141 | Control event rate (CER) | /kənˈtroʊl ɪˈvɛnt reɪt/ | Tỷ suất biến cố nhóm chứng |
| 142 | Exposed persons | /ɪkˈspoʊzd ˈpɜːrsənz/ | Người bị phơi nhiễm |
| 143 | Non-exposed persons | /nɒn ɪkˈspoʊzd ˈpɜːrsənz/ | Người không bị phơi nhiễm |
| 144 | Reciprocal | /rɪˈsɪprəkəl/ | Nghịch đảo |
| 145 | Absolute risk reduction (ARR) | /ˈæbsəluːt rɪsk rɪˈdʌkʃən/ | Giảm nguy cơ tuyệt đối |
| 146 | Baseline risk | /ˈbeɪsˌlaɪn rɪsk/ | Nguy cơ ban đầu |
| 147 | Number needed to treat (NNT) | /ˈnʌmbər ˈniːdɪd tu triːt/ | Số bệnh nhân cần điều trị (NNT) |
| 148 | Absolute risk increase (ARI) | /ˈæbsəluːt rɪsk ˈɪnkriːs/ | Tăng nguy cơ tuyệt đối |
| 149 | Side effect | /saɪd ɪˈfɛkt/ | Tác dụng phụ |
| 150 | Number needed to harm (NNH) | /ˈnʌmbər ˈniːdɪd tu hɑːrm/ | Số bệnh nhân cần để gây hại (NNH) |
| 151 | Relative risk reduction (RRR) | /ˈrɛlətɪv rɪsk rɪˈdʌkʃən/ | Giảm nguy cơ tương đối |
| 152 | Cross-product ratio | /krɒs ˈprɒdʌkt ˈreɪʃioʊ/ | Tỷ số tích chéo |
| 153 | Bivariate plots | /baɪˈvɛəriət plɒts/ | Biểu đồ hai biến |
| 154 | Scatter diagrams | /ˈskætər ˈdaɪəˌɡræmz/ | Biểu đồ phân tán |
| 155 | Data visualization | /ˈdeɪtə ˌvɪʒuəlaɪˈzeɪʃən/ | Trực quan hóa dữ liệu |
| 156 | Pre-attentive attributes | /priː əˈtɛntɪv ˈætrɪˌbjuːts/ | Thuộc tính tiền chú ý |
| 157 | Color | /ˈkʌlər/ | Màu sắc |
| 158 | Form | /fɔːrm/ | Hình thức, hình dạng |
| 159 | Movement | /ˈmuːvmənt/ | Chuyển động |
| 160 | Spatial positioning | /ˈspeɪʃəl pəˈzɪʃənɪŋ/ | Vị trí không gian |
| 161 | Length | /lɛŋθ/ | Chiều dài |
| 162 | Width | /wɪdθ/ | Chiều rộng |
| 163 | Shape | /ʃeɪp/ | Hình dạng |
| 164 | Orientation | /ˌɔːriənˈteɪʃən/ | Hướng |
| 165 | Angle | /ˈæŋɡəl/ | Góc |
| 166 | Hue | /hjuː/ | Sắc độ |
| 167 | Lightness | /ˈlaɪtnəs/ | Độ sáng |
| 168 | Saturation | /ˌsætʃəˈreɪʃən/ | Độ bão hòa |
| 169 | Intensity | /ɪnˈtɛnsɪti/ | Cường độ |
| 170 | Bubble size | /ˈbʌbəl saɪz/ | Kích thước bong bóng |
| 171 | Gradient colors | /ˈɡreɪdiənt ˈkʌlərz/ | Màu chuyển sắc |
| 172 | Misleading charts | /mɪsˈliːdɪŋ tʃɑːrts/ | Biểu đồ gây hiểu lầm |
| 173 | Complexity | /kəmˈplɛksɪti/ | Sự phức tạp |
| 174 | Labels | /ˈleɪbəlz/ | Nhãn |
| 175 | Legends | /ˈlɛdʒəndz/ | Chú giải |
| 176 | Suppression of zero | /səˈprɛʃən əv ˈzɪəroʊ/ | Loại bỏ điểm gốc không |
| 177 | Y-axis | /waɪ ˈæksɪs/ | Trục Y (trục tung) |
| 178 | X-axis | /ɛks ˈæksɪs/ | Trục X (trục hoành) |
| 179 | Magnitude of change | /ˈmæɡnɪˌtjuːd əv tʃeɪndʒ/ | Độ lớn của sự thay đổi |
| 180 | Stretching the scale | /ˈstrɛtʃɪŋ ðə skeɪl/ | Kéo dãn thang đo |
| 181 | Irrelevant percentages | /ɪˈrɛləvənt pərˈsɛntɪdʒɪz/ | Phần trăm không liên quan |
| 182 | Patient compliance | /ˈpeɪʃənt kəmˈplaɪəns/ | Sự tuân thủ của bệnh nhân |
| 183 | Insurance coverage | /ɪnˈʃʊərəns ˈkʌvərɪdʒ/ | Phạm vi bảo hiểm |
| 184 | Column percentages | /ˈkɒləm pərˈsɛntɪdʒɪz/ | Phần trăm theo cột |
| 185 | Row percentages | /roʊ pərˈsɛntɪdʒɪz/ | Phần trăm theo hàng |
| 186 | Explanatory measure | /ɪkˈsplænəˌtɔːri ˈmɛʒər/ | Thước đo giải thích |
| 187 | Interval scale | /ˈɪntərvəl skeɪl/ | Thang đo khoảng |
| 188 | Ratio scale | /ˈreɪʃioʊ skeɪl/ | Thang đo tỷ lệ |
| 189 | Line graphs | /laɪn ɡræfs/ | Đồ thị đường |
| 190 | Error plots | /ˈɛrər plɒts/ | Biểu đồ lỗi |
| 191 | Screening | /ˈskriːnɪŋ/ | Sàng lọc |
| 192 | Domestic violence | /dəˈmɛstɪk ˈvaɪələns/ | Bạo lực gia đình |
| 193 | Disparities | /dɪˈspærətiz/ | Sự chênh lệch |
| 194 | Crohn’s disease | /kroʊnz dɪˈziːz/ | Bệnh Crohn |
| 195 | Tertiary care hospital | /ˈtɜːrʃiˌɛri kɛər ˈhɒspɪtl/ | Bệnh viện tuyến ba |
| 196 | Serum sodium levels | /ˈsɪərəm ˈsoʊdiəm ˈlɛvəlz/ | Nồng độ natri huyết thanh |
| 197 | Tender joints | /ˈtɛndər dʒɔɪnts/ | Các khớp đau |
| 198 | Rheumatoid arthritis | /ˌruːməˌtɔɪd ɑːrˈθraɪtɪs/ | Viêm khớp dạng thấp |
| 199 | Reye’s syndrome | /raɪz ˈsɪnˌdroʊm/ | Hội chứng Reye |
| 200 | Reproducibility | /ˌriːprəˌduːsəˈbɪləti/ | Khả năng tái lập |